Archives: Testing client failover with Data Guard 2/switchover
All posts in this series
- Part 1: Setup
- Part 2: Switchover
- Part 3: Failover
Switchover
Planned maintenance, need to take primary server down for maintenance. The obvious Data Guard command for role change in this case is SWITCHOVER, that changes database roles in a nice coordinated way and no standby requires reinstatement (flashback) after the operation.
Lets test it from the client perspective.
Scenario: Only local SYNC standby – no ADG
First I disable and remove failtesti3 instance (remote standby) from data guard configuration, so I only have two local database instances in the configuration, in SYNC mode. Physical standby is in MOUNT mode.
DGMGRL> show configuration verbose;
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti1 - Primary database
failtesti2 - (*) Physical standby database
(*) Fast-Start Failover target
Properties:
FastStartFailoverThreshold = '25'
OperationTimeout = '30'
TraceLevel = 'USER'
FastStartFailoverLagLimit = '30'
CommunicationTimeout = '180'
ObserverReconnect = '1800'
FastStartFailoverAutoReinstate = 'TRUE'
FastStartFailoverPmyShutdown = 'TRUE'
BystandersFollowRoleChange = 'ALL'
ObserverOverride = 'FALSE'
ExternalDestination1 = ''
ExternalDestination2 = ''
PrimaryLostWriteAction = 'FAILOVER'
ConfigurationWideServiceName = 'QKNPUXMZ_CFG'
Fast-Start Failover: Enabled in Zero Data Loss Mode
Lag Limit: 30 seconds (not in use)
Threshold: 25 seconds
Active Target: failtesti2
Potential Targets: "failtesti2"
failtesti2 valid
Observer: failtest-observer
Shutdown Primary: TRUE
Auto-reinstate: TRUE
Observer Reconnect: 1800 seconds
Observer Override: FALSE
Configuration Status:
SUCCESS
To execute DGMGRL commands I log remotely in using username and password.
dgmgrl "c##dataguard/sysdgpassword@connstr" "show configuration"
Start swingbench and start the testing program.
$ charbench ...
$ python failtest.py switchover_local_only_mountAll working well, now execute switchover
date -Iseconds ; dgmgrl "c##dataguard/sysdgpassword@connstr" "switchover to failtesti2" ; date -Iseconds
2023-02-14T10:23:27+00:00
DGMGRL for Linux: Release 19.0.0.0.0 - Production on Tue Feb 7 09:29:43 2023
Version 19.16.2.0.0
Connected to "failtesti1"
Connected as SYSDG.
Performing switchover NOW, please wait...
Operation requires a connection to database "failtesti2"
Connecting ...
Connected to "failtesti2"
Connected as SYSDG.
New primary database "failtesti2" is opening...
Operation requires start up of instance "failtesti1" on database "failtesti1"
Starting instance "failtesti1"...
Please complete the following steps to finish switchover:
start up and mount instance "failtesti1" of database "failtesti1"
2023-02-14T10:24:44+00:00Alert.log from new primary failtesti2 (cleaned)
2023-02-14T10:23:35.264043+00:00 ALTER DATABASE SWITCHOVER TO PRIMARY (failtesti2) 2023-02-14T10:23:36.544532+00:00 Background Media Recovery process shutdown (failtesti2) 2023-02-14T10:23:39.430461+00:00 rmi (PID:3337550): Database role cleared from PHYSICAL STANDBY [kcvs.c:1114] Switchover: Complete - Database mounted as primary 2023-02-14T10:23:41.542728+00:00 ALTER DATABASE OPEN 2023-02-14T10:23:46.293995+00:00 Completed: ALTER DATABASE OPEN ALTER PLUGGABLE DATABASE ALL OPEN 2023-02-14T10:23:48.984619+00:00 SOEFAIL(3):Started service soe/soe/soe.prod1.dbs 2023-02-14T10:23:48.985369+00:00 Pluggable database SOEFAIL opened read write Completed: ALTER PLUGGABLE DATABASE ALL OPEN
Alert.log from old primary failtesti1
2023-02-14T10:23:31.344766+00:00 ALTER DATABASE SWITCHOVER TO 'failtesti2' 2023-02-14T10:23:32.055470+00:00 ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY [Process Id: 2418351] (failtesti1) 2023-02-14T10:23:33.067341+00:00 Primary will check for some target standby to have received all redo RSM0 (PID:2418351): Waiting for target standby to apply all redo 2023-02-14T10:23:39.432887+00:00 RSM0 (PID:2418351): Switchover complete. Database shutdown required TMI: dbsdrv switchover to target END 2023-02-14 10:23:39.432896 Completed: ALTER DATABASE SWITCHOVER TO 'failtesti2'
Looking at the alert.log I see that 2023-02-14T10:23:31.344766+00:00 old primary database initiated the switchover procedure and 2023-02-14T10:23:48.985369+00:00 the new primary database was ready to accept connections. Taking 17.64s.
Lets see what client saw at the same time.
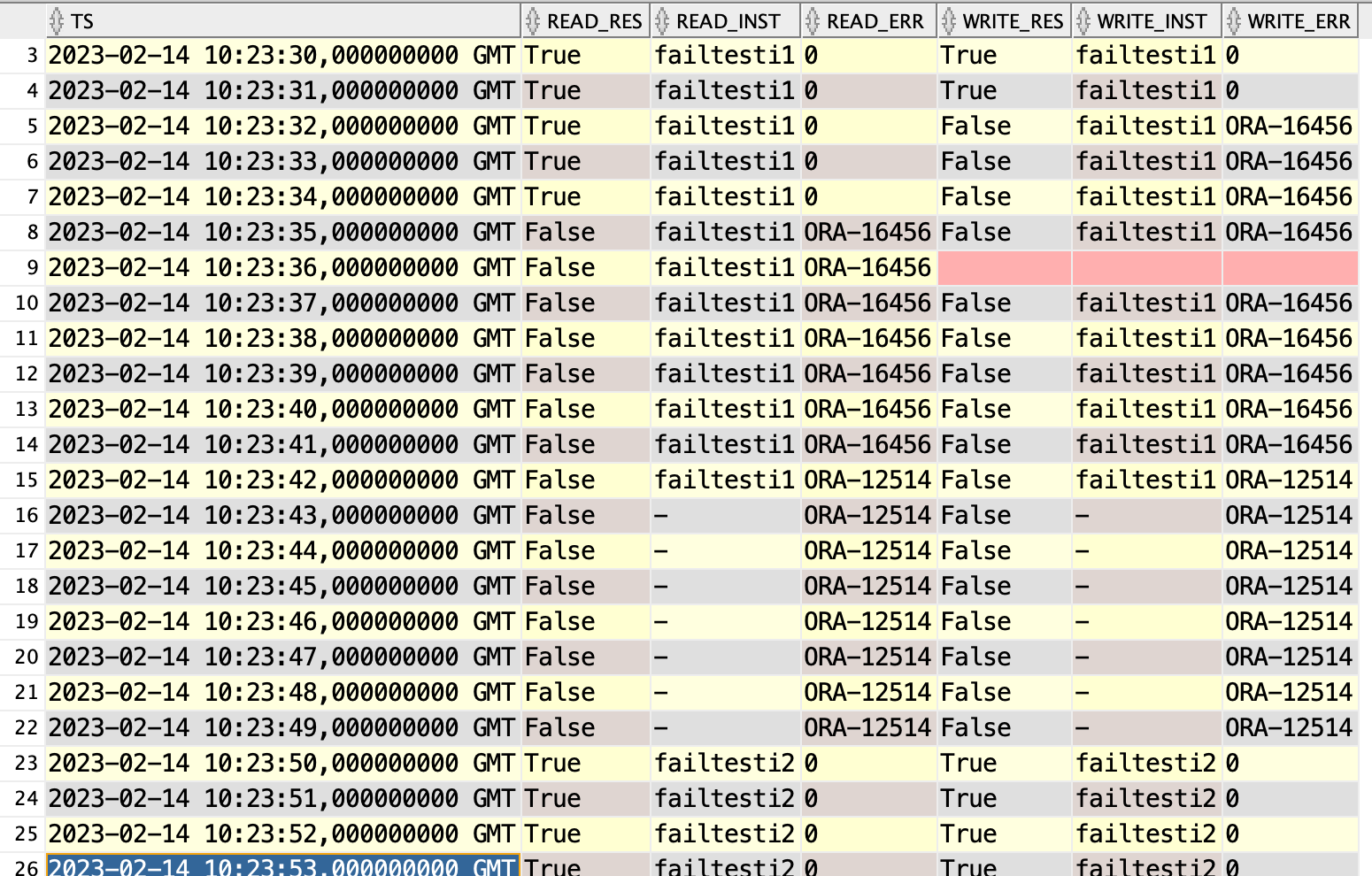
What I can see from it is that reads are allowed for a few seconds after switchover was initiated, making total downtime 14 seconds. Writes are closed immediately, so downtime for the client 17s. I actually expeted reads to be allowed for 4 more seconds, right until 2023-02-14T10:23:39 when alert.log reports Switchover complete. Something is not right, must retest this.
Scenario: Only local SYNC standby – with ADG
Lets repeat the test, but now the target standby CDB is open in READ ONLY mode. But pluggable databases are in MOUNTED mode (to prevent the service starting). So Active Data Guard is activated (LICENSE WARNING!).
SQL>sho pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 SOEFAIL MOUNTED
Data Guard status
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti2 - Primary database
failtesti1 - (*) Physical standby database
Fast-Start Failover: Enabled in Zero Data Loss Mode
Configuration Status:
SUCCESS (status updated 29 seconds ago)
Executing “switchover to failtesti1”
date -Iseconds ; dgmgrl "c##dataguard/sysdgpassword@connstr" "switchover to failtesti1" ; date -Iseconds 2023-02-14T10:39:13+00:00 Connected to "failtesti1" Connected as SYSDG. Performing switchover NOW, please wait... New primary database "failtesti1" is opening... Operation requires start up of instance "failtesti2" on database "failtesti2" Starting instance "failtesti2"...
Alert.log from new primary failtesti1
2023-02-14T10:39:19.896716+00:00 ALTER DATABASE SWITCHOVER TO PRIMARY (failtesti1) 2023-02-14T10:39:21.177020+00:00 Background Media Recovery process shutdown (failtesti1) 2023-02-14T10:39:27.007310+00:00 Completed: alter pluggable database all close immediate 2023-02-14T10:39:32.184760+00:00 CLOSE: all sessions shutdown successfully. Completed: alter pluggable database all close immediate 2023-02-14T10:39:33.404812+00:00 Switchover: Complete - Database mounted as primary TMI: kcv_commit_to_so_to_primary Switchover from physical END 2023-02-14 10:39:33.532617 SWITCHOVER: completed request from primary database. 2023-02-14T10:39:37.033131+00:00 ALTER DATABASE OPEN 2023-02-14T10:39:43.467549+00:00 SOEFAIL(3):Started service soe/soe/soe.prod1.dbs 2023-02-14T10:39:43.468294+00:00 Pluggable database SOEFAIL opened read write 2023-02-14T10:39:43.694199+00:00 Completed: ALTER DATABASE OPEN ALTER PLUGGABLE DATABASE ALL OPEN Completed: ALTER PLUGGABLE DATABASE ALL OPEN
Alert.log from old primary failtesti2
2023-02-14T10:39:16.016238+00:00 ALTER DATABASE SWITCHOVER TO 'failtesti1' 2023-02-14T10:39:16.711884+00:00 ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY [Process Id: 2441633] (failtesti2) 2023-02-14T10:39:17.723971+00:00 RSM0 (PID:2441633): Waiting for target standby to apply all redo 2023-02-14T10:39:19.547345+00:00 Switchover: Complete - Database shutdown required TMI: kcv_switchover_to_target convert to physical END 2023-02-14 10:39:19.567773 RSM0 (PID:2441633): Sending request(convert to primary database) to switchover target failtesti1 2023-02-14T10:39:33.534253+00:00 RSM0 (PID:2441633): Switchover complete. Database shutdown required
According to alert.log switchover took from 2023-02-14T10:39:16.016238+00:00 to 2023-02-14T10:39:43.467549+00:00 (when service opened), so 27.45s… surprise, did not expect this.
And now the client perspective.
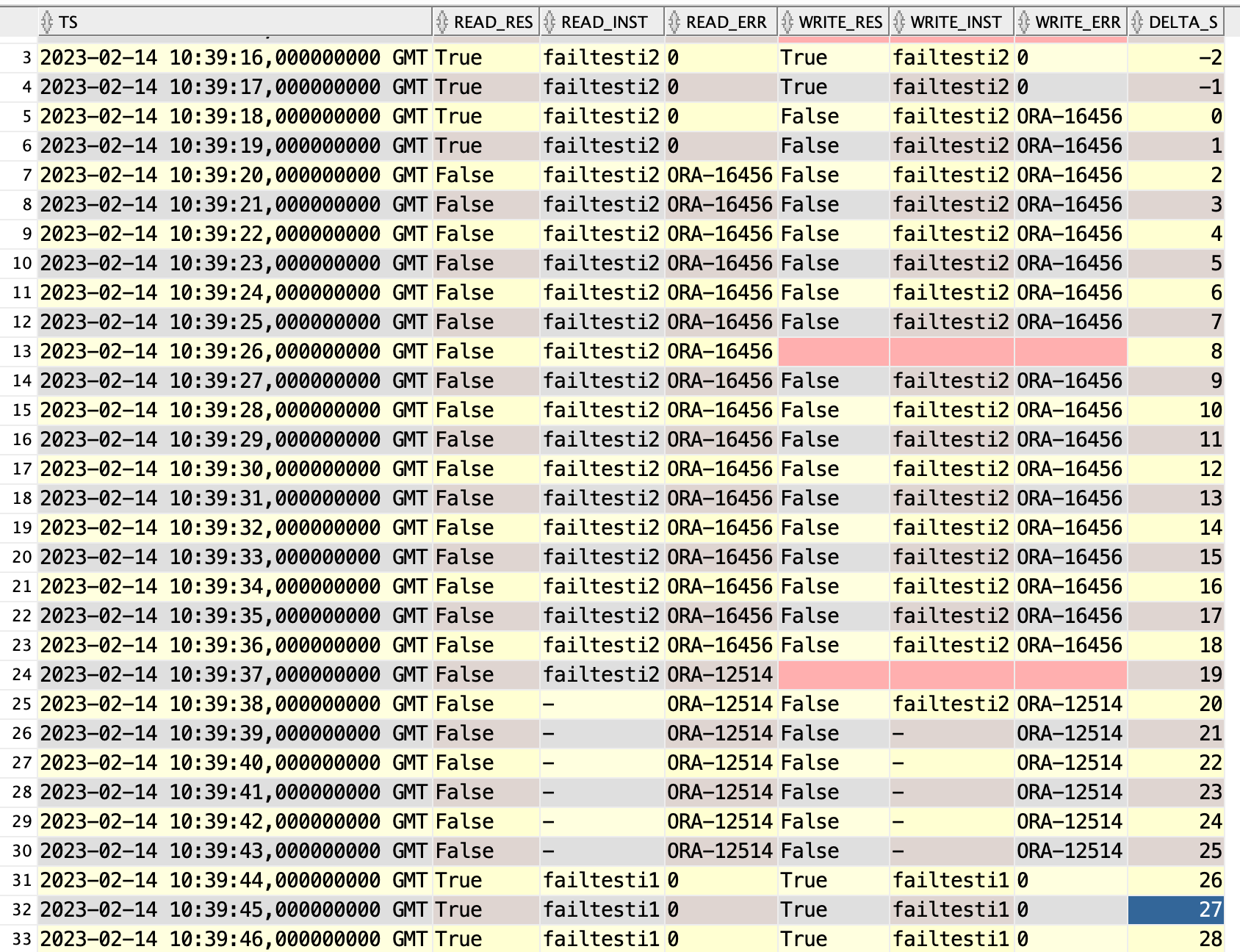
Same story as before, but having the target database open (Active Data Guard) adds about 9-10s to the downtime. From alert.log it looks like it needs to close all read only pluggable databases before switchover completes.
Scenario: Local SYNC standby and remote ASYNC standby – no ADG
Now in addition to local SYNC standby, I’ll add a remote ASYNC standby failtesti3 in the configuration, which is 53ms away (ping time). But I’m still ony interested in the role change between failtesti1 and failtesti2.
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti1 - Primary database
failtesti2 - (*) Physical standby database
failtesti3 - Physical standby database
Fast-Start Failover: Enabled in Zero Data Loss Mode
Configuration Status:
SUCCESS (status updated 31 seconds ago)
Start the tests and do switchover.
date -Iseconds ; dgmgrl "c##dataguard/sysdgpassword@connstr" "switchover to failtesti2" ; date -Iseconds 2023-02-24T10:18:13+00:00 Connected to "failtesti1" Connected as SYSDG. Performing switchover NOW, please wait... Operation requires a connection to database "failtesti2" Connecting ... Connected to "failtesti2" Connected as SYSDG. New primary database "failtesti2" is opening... Operation requires start up of instance "failtesti1" on database "failtesti1" Starting instance "failtesti1"... 2023-02-24T10:19:35+00:00
From client perspective
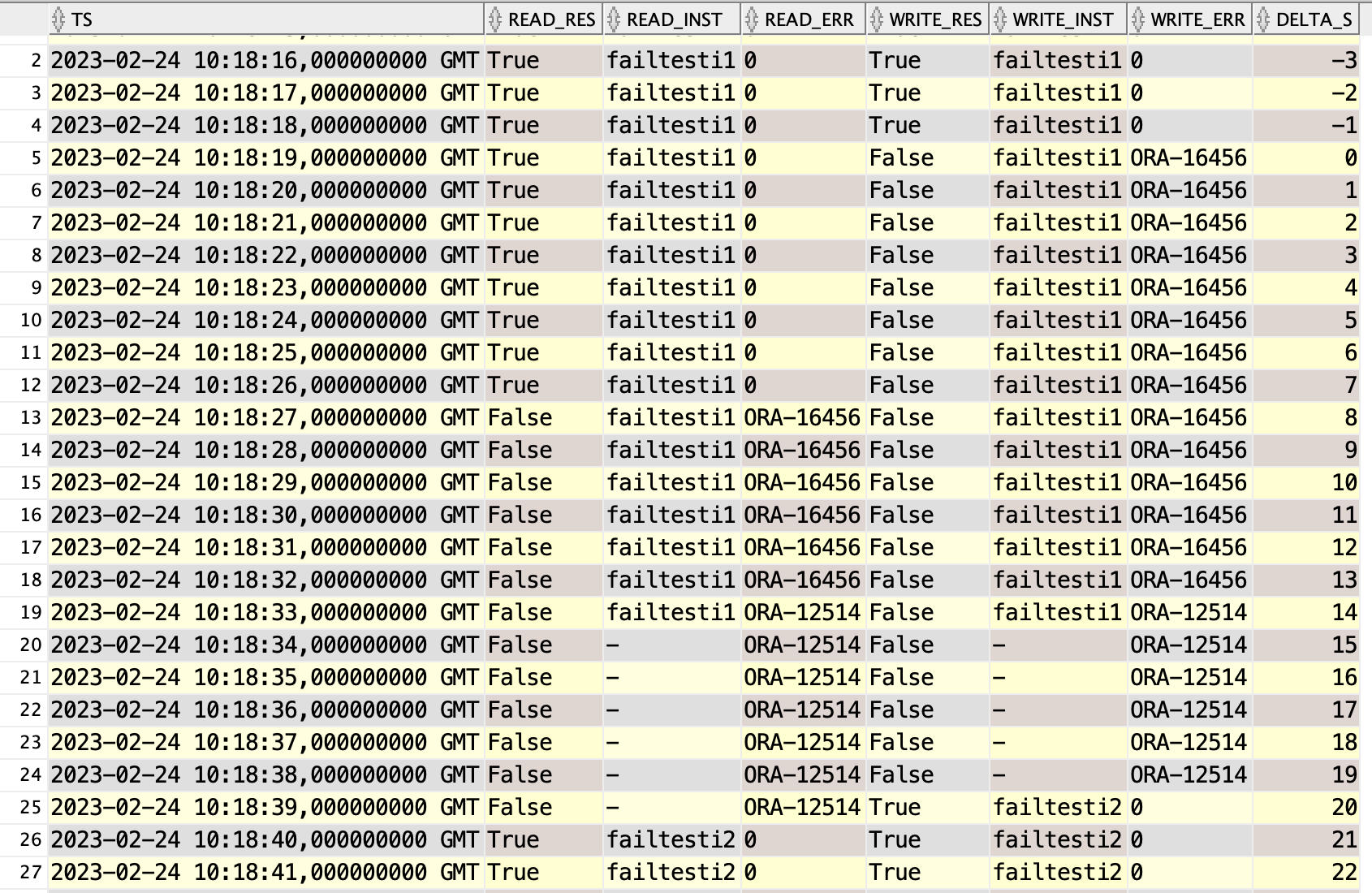
The remote standby made little difference. It added a few seconds to the switchover time, during which the old primary was still readable. During switchover Data Guard Broker must sync the configuration to all standbys.
Alert log from old primary failtest1
2023-02-24T10:18:18.128228+00:00 ALTER DATABASE SWITCHOVER TO 'failtesti2' 2023-02-24T10:18:18.827865+00:00 ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY [Process Id: 3284632] (failtesti1) ... 2023-02-24T10:18:25.855408+00:00 Switchover: Complete - Database shutdown required 2023-02-24T10:18:30.367681+00:00 RSM0 (PID:3284632): Switchover complete. Database shutdown required Completed: ALTER DATABASE SWITCHOVER TO 'failtesti2'
I see that reads on the old primary were allowed right until switchover was complete. Writes and disabled immediately. This is the behaviour I expect.
Scenario: Local SYNC standby and remote standby with lagging apply
Here my goal is to see what happens when the remote standby is lagging behind. Will it affect the local switchover? To simulate that I’ll stop apply on failtesti3 and let swingbench run for a longer time before initiating switchover.
DGMGRL> edit database failtesti3 set state='apply-off';
-- run swingbenh for a few hours
DGMGRL> edit database failtesti3 set state='apply-on';
-- immediately run switchoverBefore the test lets check how big the lag is on the remote standby. Before switchover I have over 3h lag, with over 40GB logs to apply on failtesti3.
DGMGRL> show configuration;
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti2 - Primary database
failtesti1 - (*) Physical standby database
failtesti3 - Physical standby database
Fast-Start Failover: Enabled in Zero Data Loss Mode
Configuration Status:
SUCCESS (status updated 37 seconds ago)
DGMGRL> edit database failtesti3 set state='apply-on';
Succeeded.
DGMGRL> show database failtesti3;
Database - failtesti3
Role: PHYSICAL STANDBY
Intended State: APPLY-ON
Transport Lag: 0 seconds (computed 0 seconds ago)
Apply Lag: 3 hours 7 minutes 36 seconds (computed 0 seconds ago)
Average Apply Rate: 88.35 MByte/s
Real Time Query: ON
Instance(s):
failtesti3
Database Warning(s):
ORA-16853: apply lag has exceeded specified threshold
Database Status:
WARNING
-- switchover
2023-02-24T13:37:45+00:00
Connected to "failtesti2"
Connected as SYSDG.
Performing switchover NOW, please wait...
Operation requires a connection to database "failtesti1"
Connecting ...
Connected to "failtesti1"
Connected as SYSDG.
New primary database "failtesti1" is opening...
Operation requires start up of instance "failtesti2" on database "failtesti2"
Starting instance "failtesti2"...
2023-02-24T13:39:06+00:00
DGMGRL> show database failtesti3;
Database - failtesti3
Role: PHYSICAL STANDBY
Intended State: APPLY-ON
Transport Lag: 0 seconds (computed 0 seconds ago)
Apply Lag: 2 hours 28 minutes 47 seconds (computed 0 seconds ago)
Average Apply Rate: 110.65 MByte/s
Real Time Query: ON
Instance(s):
failtesti3
After the switchover I still have plenty of lag in failtesti3 to apply.
What did the client see?
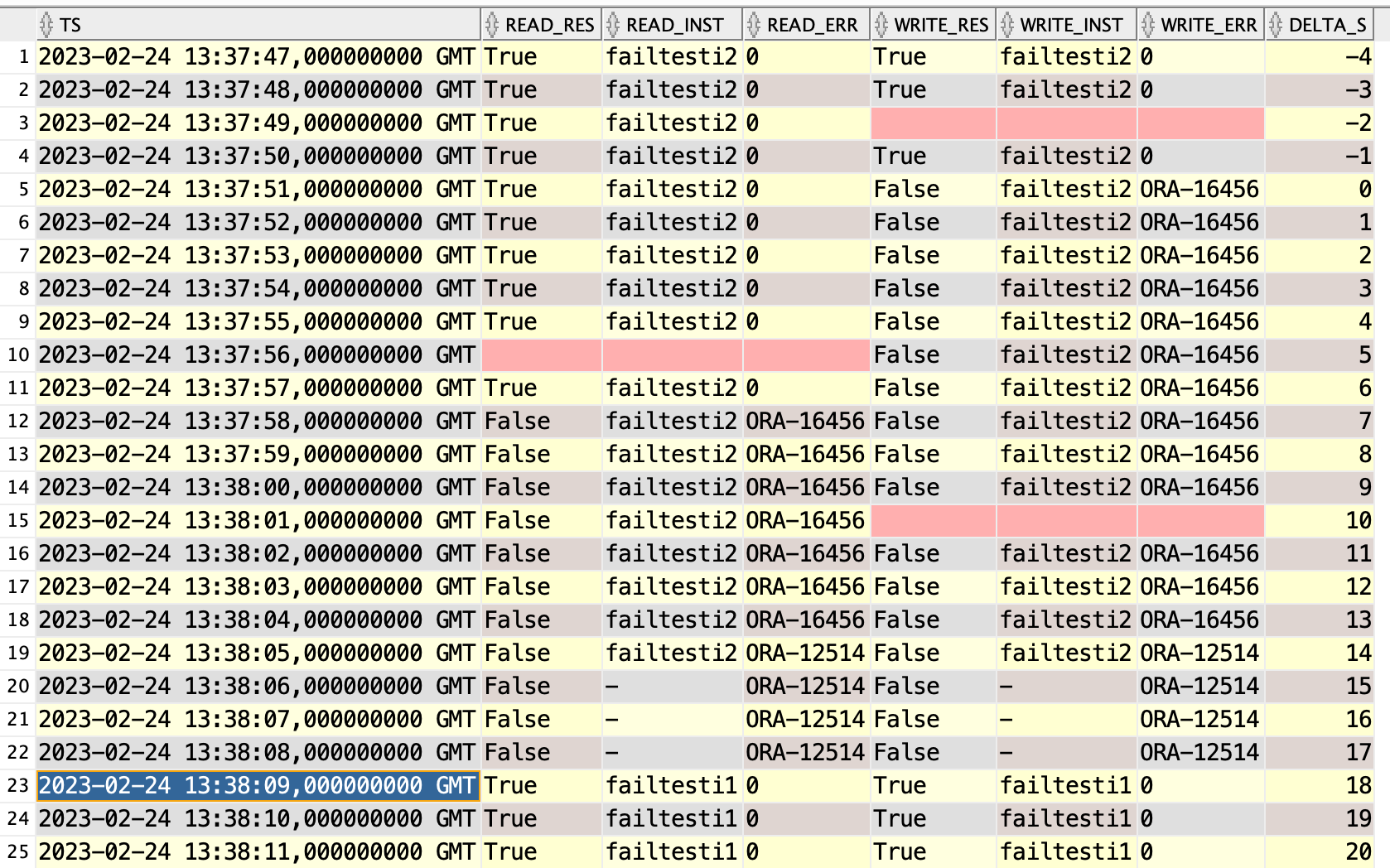
I don’t see any real difference to the test without the lag.
Scenario: Local SYNC standby and remote standby with lagging transport
Lets try again, but now I’ll change transport to remote failtesti3 standby to ARCH mode, expecting that during switchover it would need to transport a few GB.
DGMGRL> edit database failtesti3 set property logxptmode='arch';
-- run swingbench, so it has quite a few GB of redo collected before logswitch
2023-02-24T14:14:43+00:00
DGMGRL> switchover to failtesti2;
Connected to "failtesti1"
Connected as SYSDG.
Performing switchover NOW, please wait...
Operation requires a connection to database "failtesti2"
Connecting ...
Connected to "failtesti2"
Connected as SYSDG.
New primary database "failtesti2" is opening...
Operation requires start up of instance "failtesti1" on database "failtesti1"
Starting instance "failtesti1"...
2023-02-24T14:19:49+00:00Finally… significantly slower switchover, taking minutes. How did the client see it?
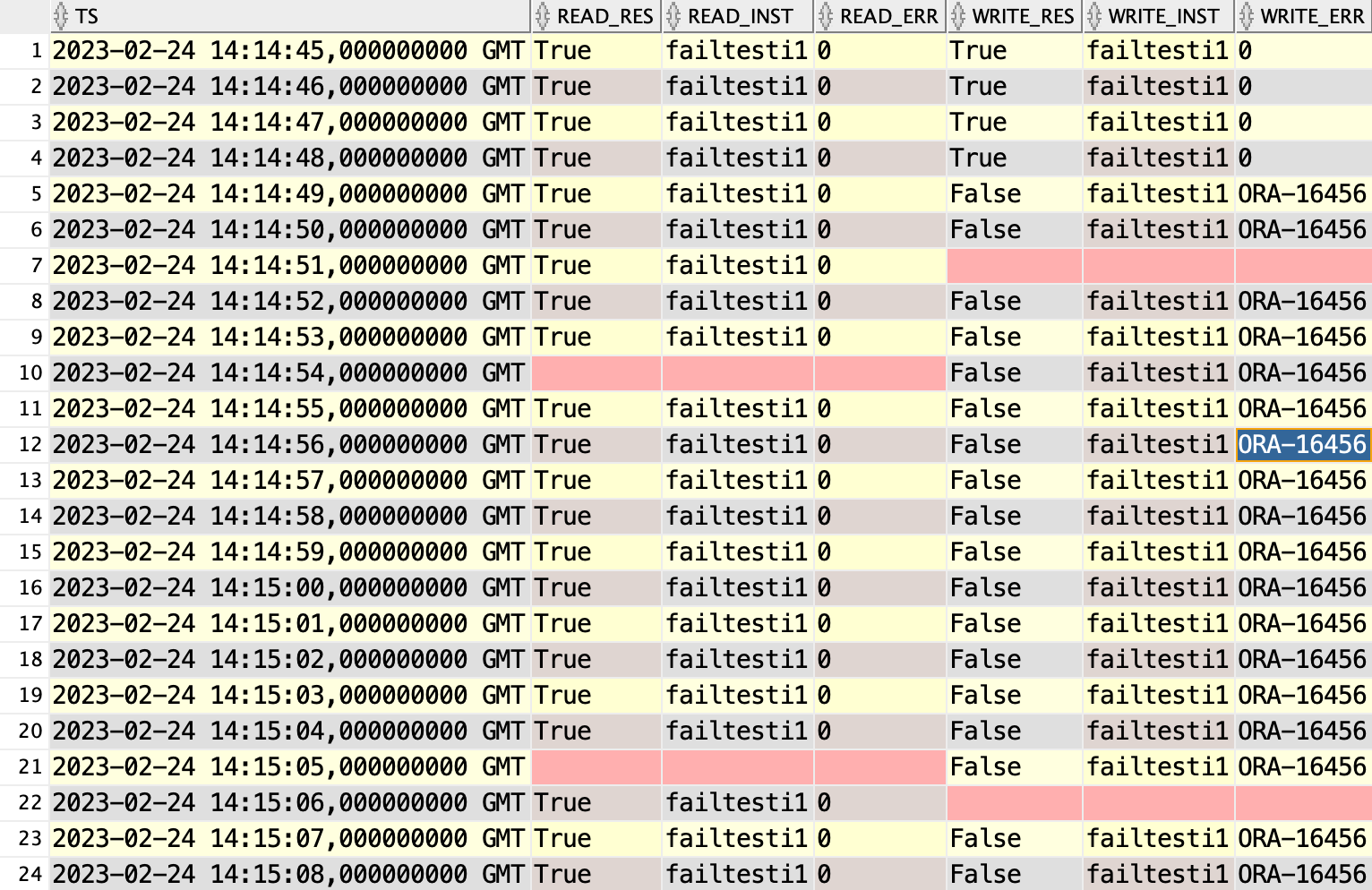
And it continues this way for minutes… until
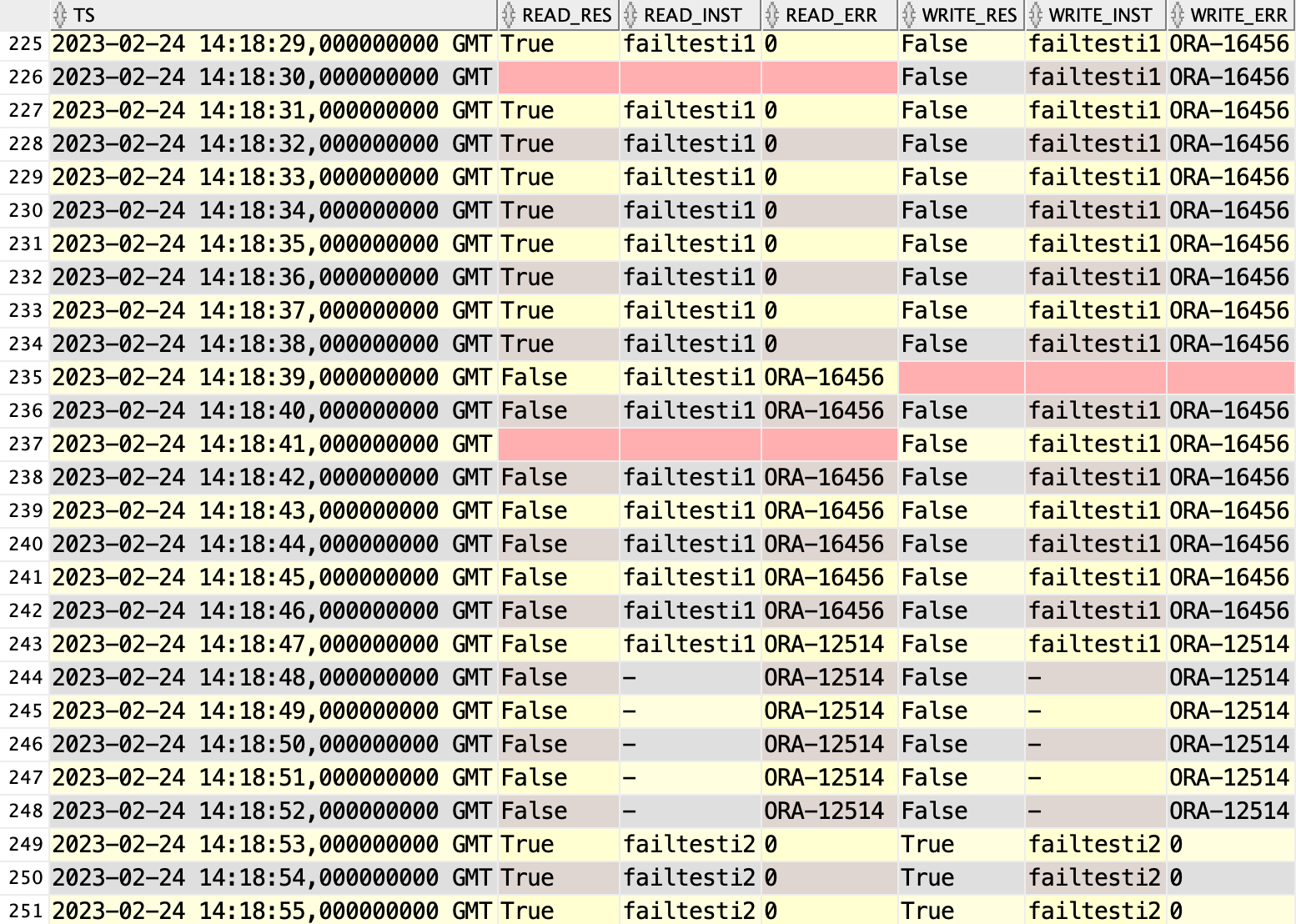
Read queries were still only down for about 13s, but writes were down for 4min 3s! That is the time it took to send the archived logfile to the remote standby. In my test the logfile was 3GB is size.
Lets look at the old primary alert.log
2023-02-24T14:14:48.009629+00:00 ALTER DATABASE SWITCHOVER TO 'failtesti2' 2023-02-24T14:14:48.714313+00:00 ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY [Process Id: 2332229] (failtesti1) 2023-02-24T14:14:49.727293+00:00 RSM0 (PID:2332229): Generating and shipping final logs to target standby Switchover End-Of-Redo Log thread 1 sequence 858 has been fixed Switchover: Primary highest seen SCN set to 0x0000000017d7d99f RSM0 (PID:2332229): Noswitch archival of T-1.S-858 RSM0 (PID:2332229): End-Of-Redo Branch archival of T-1.S-858 RSM0 (PID:2332229): LGWR is actively archiving to LAD:2 2023-02-24T14:18:38.393413+00:00 RSM0 (PID:2332229): Archiving is disabled due to current logfile archival Primary will check for some target standby to have received all redo RSM0 (PID:2332229): Waiting for target standby to apply all redo 2023-02-24T14:18:43.333433+00:00 RSM0 (PID:2332229): Switchover complete. Database shutdown required
I don’t really see any log entry that specifically says that it is waiting for the remote standby to receive the latest redo, although this is what it must be waiting on.
Anyway, good thing to know in case of performing switchovers. Make sure ALL standbys in configuration have minimal amount of redo to ship during switchover.
RETEST! Only local SYNC standby – no ADG
Don’t really understand why in my first test without any remote long distance standby, reads were stopped too early. I expected the old standby to be readable up until the very last moment of the switchover. Lets try again.
DGMGRL> remove database failtesti3;
Removed database "failtesti3" from the configuration
DGMGRL> show configuration;
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti2 - Primary database
failtesti1 - (*) Physical standby database
Fast-Start Failover: Enabled in Zero Data Loss Mode
Configuration Status:
SUCCESS (status updated 11 seconds ago)
2023-02-24T14:53:48+00:00
DGMGRL> switchover to failtest1;
Connected to "failtesti2"
Connected as SYSDG.
Performing switchover NOW, please wait...
Operation requires a connection to database "failtesti1"
Connecting ...
Connected to "failtesti1"
Connected as SYSDG.
New primary database "failtesti1" is opening...
Operation requires start up of instance "failtesti2" on database "failtesti2"
Starting instance "failtesti2"...
2023-02-24T14:55:06+00:00
What did the client see?

A little bit faster this time. 12s downtime for reads, 15s downtime for writes.
Take-aways
- During switchover reads are permitted as long as possible, writes are blocked immediately when switchover starts with ORA-16456.
- Having Active Data Guard database as the switchover target adds about 10s to the switchover time.
- Having far away ASYNC standby databases will add a few seconds to the switchover time. Minimal.
- But if one of the BYSTANDER remote standby databases is having a transport lag, during switchover writes will be blocked for quite a long time, depending on how long it will take to transport the missing redo. Apply lag did not have the same effect.
Next…
Failover methods
Archives: Testing client failover with Data Guard Fast-Start Failover 1/setup
All posts in this series
- Part 1: Setup
- Part 2: Switchover
- Part 3: Failover
Data Guard setup
My end goal is to find out how fast database clients (applications) can resume work (reading and writing) after Data Guard role change operation – either it happens as a planned or unplanned operation. Testing different options to find the shortest downtime – results apply for my environment only, your results will vary.
I’m doing it just to increase my knowledge about different Data Guard scenarios.
My database setup
I’m ONLY interested in the role change operation between instances failtesti1 and failtesti2. Whitch are in the same DC, different availability zones (ping 0.165 ms avg). They equal in every way and are intended to service application read+write traffic as primary databases. These two instances are in SYNC mode.
During the test I will also throw in a remote standby database failtesti3 that is located a few thousand km away (53ms ping). This remote standby is in ASYNC or ARCH mode. failtesti3 is only a BYSTANDER during all tests.
DGMGRL> show configuration verbose;
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti1 - Primary database
failtesti2 - (*) Physical standby database
failtesti3 - Physical standby database
(*) Fast-Start Failover target
Properties:
FastStartFailoverThreshold = '25'
OperationTimeout = '30'
TraceLevel = 'USER'
FastStartFailoverLagLimit = '30'
CommunicationTimeout = '180'
ObserverReconnect = '1800'
FastStartFailoverAutoReinstate = 'TRUE'
FastStartFailoverPmyShutdown = 'TRUE'
BystandersFollowRoleChange = 'ALL'
ObserverOverride = 'FALSE'
ExternalDestination1 = ''
ExternalDestination2 = ''
PrimaryLostWriteAction = 'FAILOVER'
ConfigurationWideServiceName = 'QKNPUXMZ_CFG'
Fast-Start Failover: Enabled in Zero Data Loss Mode
Lag Limit: 30 seconds (not in use)
Threshold: 25 seconds
Active Target: failtesti2
Potential Targets: "failtesti2"
failtesti2 valid
Observer: failtest-observer
Shutdown Primary: TRUE
Auto-reinstate: TRUE
Observer Reconnect: 1800 seconds
Observer Override: FALSE
Configuration Status:
SUCCESSServices
Both CDB and PDB have a simple service and on database open trigger created, to start the service when database opens.
exec dbms_service.create_service('dbauser_failtest','dbauser_failtest');
exec dbms_service.start_service('dbauser_failtest');
CREATE OR REPLACE TRIGGER sys.cdb_start_services AFTER STARTUP OR DB_ROLE_CHANGE ON DATABASE
DECLARE
v_srv_name varchar2(30):= 'dbauser_failtest';
cnt NUMBER;
BEGIN
SELECT count(*) INTO cnt FROM v$active_services WHERE name = v_srv_name;
IF cnt = 0 THEN
dbms_service.start_service(v_srv_name);
END IF;
END;
/For PDB application use
alter session set container=soefail;
-- Lets create a simple service
exec dbms_service.create_service('soe','soe');
-- Now lets create one service with Application Continuity turned on
DECLARE
new_service_params dbms_service.svc_parameter_array;
p_srv_name varchar2(20):= 'soe_ac';
BEGIN
new_service_params('FAILOVER_TYPE'):= 'AUTO';
new_service_params('REPLAY_INITIATION_TIMEOUT'):= 1800;
new_service_params('RETENTION_TIMEOUT'):= 86400;
new_service_params('FAILOVER_DELAY'):= 5;
new_service_params('FAILOVER_RETRIES'):= 10;
new_service_params('FAILOVER_RESTORE'):= 'AUTO';
new_service_params('commit_outcome'):= 'true';
new_service_params('aq_ha_notifications'):= 'true';
dbms_service.create_service(p_srv_name, p_srv_name);
dbms_service.modify_service(p_srv_name, new_service_params);
dbms_service.start_service(p_srv_name);
END;
/
CREATE OR REPLACE TRIGGER sys.pdb_start_services AFTER STARTUP ON DATABASE
BEGIN
dbms_service.start_service('soe');
dbms_service.start_service('soe_ac');
dbms_service.start_service('dbauser_soefail');
END;
/Load swingbench SOE schema
swingbench/bin/oewizard -cl -cs tcp://failtest-1/dbauser_soefail.prod1.dbs -dba dbauser -dbap dbauser -u soe -p soe -scale 1 -create -tc 2 -ts soeCommand to run swingbench test
bin/charbench -cs "(description=(failover=on)(connect_timeout=2)(transport_connect_timeout=1 sec)(address_list=(address=(protocol=tcp)(host=failtest-1)(port=1521))(address=(protocol=tcp)(host=failtest-2)(port=1521)))(connect_data=(service_name=soe.prod1.dbs)))" \
-u soe -p soe -uc 4 -c SOE_Server_Side_V2.xmlDuring all test I have swingbench running at around 1600 TPS – which is enough for my small setup to keep the CPUs 40% idle. I want databases under load, but still enough free CPU time for it not to affect the test.
avg-cpu: %user %nice %system %iowait %steal %idle
52.11 0.05 5.96 7.39 0.00 34.49
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
vdc 33.00 1506.40 1.68 9.85 66.00 0.00 66.67 0.00 0.95 1.48 2.49 52.07 6.70 0.40 61.38
vdd 38.80 1487.80 1.84 8.83 72.00 0.60 64.98 0.04 0.84 1.42 2.37 48.66 6.08 0.40 61.00
avg-cpu: %user %nice %system %iowait %steal %idle
50.33 0.05 4.84 9.33 0.00 35.44
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
vdc 29.80 1388.80 1.41 8.91 23.60 1.20 44.19 0.09 0.84 2.05 3.11 48.32 6.57 0.42 59.42
vdd 34.20 1417.40 1.37 8.55 21.00 0.20 38.04 0.01 0.72 1.82 2.86 41.12 6.18 0.42 60.88
The client
I wrote a simple client in Python that will connect two threads to the database – one that only reads and one that only writes, in separate threads. And the program will record all errors the client experiences during the test and in case connection becomes unusable – reconnect to the database. Results are recorded in CSV file to be analysed later.
Side note: The client is indeed using the new python-oracledb module, but since it is currently not complete, specially in the HA area – I’m using it in thick mode with Instantclient 21.9.
Access the test client code here (github.com)
Examples queries for data analytics are also part of the github repository.
The plan
The next post will be about switchover… then about failover. Maybe more, who knows.
Archives: Downgrade Oracle Linux 8 from UEKr7 kernel to UEKr6
I noticed that the latest Oracle Linux 8 U7 Cloud Image from https://yum.oracle.com/oracle-linux-templates.html comes with UEKr7 kernel by default (5.15.0). But this is not yet supported by Oracle Database 19c and it is also missing for example ceph filesystem kernel module.
So here are instructions how to downgrade kernel on OEL8.
First enable UEKr6 tum repository and disable UEKr7 respository. I’m not going to write these instructions, since the copy I have uses our own internal repositories and not public ones.
After that execute:
update file /etc/sysconfig/kernel and set
DEFAULTKERNEL=kernel-uek
# Install old UEKr6 kernel
dnf install kernel-uek
# Remove the new UEKr7 kernel
rpm -e kernel-uek-core
# Regenerate GRUB config
grub2-mkconfig -o /boot/grub2/grub.cfgCategories
- Blog entry
 (101)
(101)
- Event (5)