Tag: apex
- Written by: ilmarkerm
- Category: Blog entry
- Published: April 11, 2026
I currently have a customer who wishes to move their internal APEX application into a cloud based hosting, with quite tight budget constraints – and at the same time still need to treat it as production service.
After comparing many options, none which were perfect, the option that we are going for is Oracle Autonomous database APEX workload type. It is significantly cheaper than the full blown Autonomous Database, but it does come with its own quite unique challenges that we need to overcome. APEX service limitations are documented here
The main limitation – there is no connectivity via SQL*Net, all interactions must be done over HTTPS. Everything, including development of database application and deployments.
Side-effect of this restriction is also that there is no-way to have a custom URL (vanity URL) for your application that would also support APEX social login feature (OAuth/OpenID). To overcome that limitation in a full Autonomous Database installation, people usually deploy their own ORDS in front of the Oracle cloud database service. This solution is not usable here.
I will write a few blog posts, on how to work within the restrictions of the APEX workload type database and still keep most of the developer comforts.
Connecting to the database
To work with the database schema you are mainly expected to use the built in APEX SQL workspace and Database Actions SQL Developer web. Mostly enough, but I think we all prefer using our own preferred database clients. Also it is not possible to automate tasks and deploys via the web page.
A few years ago Oracle introduced REST JDBC driver that talks to the database over ORDS SQL endpoint, via HTTP protocol. This ORDS endpoint is accessible, so lets try using it.
The REST JDBC driver does come with restrictions, the main one being that the driver is stateless and does not support transactions. You can read about the driver and its restrictions here
Create ORDS enabled schema
Open Autonomous AI Database and go to Tool configuration. There you see Web access (ORDS) and open its Public access URL. Open SQL Developer web and log in as ADMIN.
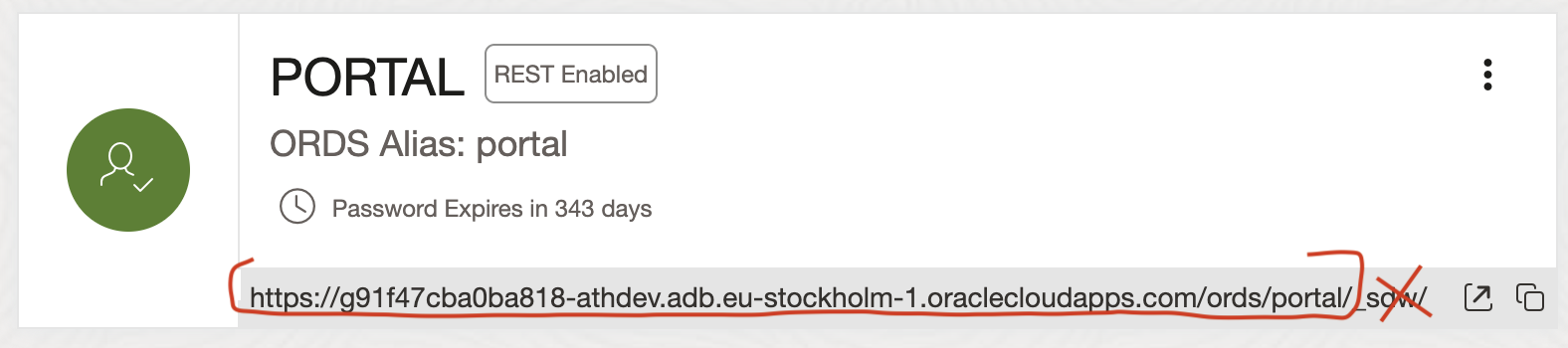
Open Administration > Database users and enable schema you want to log in as REST enabled. And copy the REST URL for this schema, minus the last _sdw/ part.
SQLcl
It is possible to connect to the ORDS SQL endpoint using SQLcl, Jeff Smith blogged about it here. Although not all SQLcl functions are available. For example Liquibase and connection manager are not available.
Here I’m using SQLcl 26.1.
- Start SQLcl with /nolog flag
- CONNECT schemaname@RESTUrl
- Or CONNECT schemaname/password@RESTUrl
ilmarkerm@Ilmars-iMac bin % ./sql /nolog
SQLcl: Release 26.1 Production on Sat Apr 11 09:21:40 2026
Copyright (c) 1982, 2026, Oracle. All rights reserved.
SQL> connect portal@https://g91f47cba0ba818-athdev.adb.eu-stockholm-1.oraclecloudapps.com/ords/portal/
Password? (**********?) **********************
Connected.
SQL> select user, sys_context('userenv','instance_name');
USER SYS_CONTEXT('USERENV','INSTANCE_NAME')
_________ _________________________________________
PORTAL fcehldyf3I can execute usual SQL commands.
SQL> create table t (id number);
Table T created.
SQL> insert into t (id) values (1);
1 row inserted.
SQL> select * from t;
ID
_____
1
SQL> begin
2 for i in 1..100000 loop
3 insert into t (id) values (i);
4 end loop;
5 end;
6* /
PL/SQL procedure successfully completed.
SQL> select count(*) from t;
COUNT(*)
___________
100001
SQL> truncate table t;
Table T truncated.But the REST driver is stateless, so no transactions (between different calls – inside the same call they work).
SQL> insert into t (id) values (2000000002);
1 row inserted.
SQL> rollback;
Rollback complete.
SQL> select * from t;
ID
_____________
2000000002
SQL> begin
2 insert into t (id) values (30000003);
3 rollback;
4 end;
5* /
PL/SQL procedure successfully completed.
SQL> select * from t;
ID
_____________
2000000002You cannot use SQLcl connection manager for saving the connections.
SQL> conn -save portaldev portal@https://g91f47cba0ba818-athdev.adb.eu-stockholm-1.oraclecloudapps.com/ords/portal/
Connections of type OREST are not supported for saving
Warning: You are no longer connected to ORACLE.Also built in Liquibase commands give a NullPointer.
SQL> lb generate-changelog
Null Pointer please log a bug.
liquibase.exception.CommandExecutionException: Cannot invoke "String.toUpperCase()" because the return value of "java.sql.DatabaseMetaData.getSQLKeywords()" is nullGUI
I haven’t been successful at connecting DBeaver nor SQL Developer using the Oracle REST driver. DBeaver just gives a lot of internal JDBC errors even if I strip it down to bare minimum of supported features.
java.lang.NullPointerException: Cannot invoke "java.sql.Statement.execute(String)" because the return value of "org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.getOriginal()" is nullI’ll leave it like that.
- Written by: ilmarkerm
- Category: Blog entry
- Published: February 23, 2025
To enable edit mode on Interactive Grid immediately when page loads (to save users a double click), you can create a dynamic action to run custom JavaScript on page load:
- Set Static ID on your Interactive Grid region – lets call it MYIG1
- Create a Dynamic Action on event Page Load and on True event let it execute the following JavaScript Code
apex.region("MYIG1").call("getActions").set("edit", true);Up to this part all is well and if you page is not very log, problem solved. But if the page is longer you will notice a side-effect – the page gets automatically scrolled to set focus on the Interactive Grid. To fix it append a scroll up code to the JavaScript snippet above, so a full example would look like this.
apex.region("MYIG1").call("getActions").set("edit", true);
$("html, body").delay(500);
$("html, body").animate({ scrollTop: 0 },0);That little bit of delay is necessary, otherwise scrolling will not work. It will also introduce a little bit of “page flickering”, but at least the page focus is back on top when page is loaded.
Tested with APEX 24.2.
- Written by: ilmarkerm
- Category: Blog entry
- Published: August 21, 2024
I previously wrote about how after successfully downgrading APEX users still get the error “Application Express is currently unavailable”. I now ran to the same issue again, with newer versions and the procedure how ORDS detects is APEX is currently being patched has changed.
This post is about downgrading to APEX 23.1 and ORDS 24.1.
After completing APEX downgrade to 23.1, ORDS 24.1 still reported that “Application Express is currently unavailable”. I followed my own previous blog and flipped the APEX internal patching status to APPLIED, but no luck this time. PANIC! I turned on tracking for ORDS sessions and this PL/SQL block seems to be the culprit.
DECLARE
NM OWA.VC_ARR := :1 ;
VL OWA.VC_ARR := :2 ;
L_PATCH VARCHAR2(10) := null;
L_VERSION VARCHAR2(100) := null;
SCHEMA VARCHAR2(30);
PART1 VARCHAR2(30);
PART2 VARCHAR2(30);
DBLINK VARCHAR2(30);
PART1_TYPE NUMBER(10);
OBJECT_NUM NUMBER(10);
BEGIN
OWA.INIT_CGI_ENV(:3 , NM, VL);
HTP.INIT;
HTP.HTBUF_LEN := 63;
--CHECK THE SCHEMA OVERRIDE FOR PL/SQL GATEWAY APPLICATION DETAILS
DECLARE
GATEWAY_DETAILS VARCHAR2(2000) := q'[ SELECT
(SELECT VALUE FROM ORDS_METADATA.USER_ORDS_PROPERTIES WHERE KEY = 'plsql.gateway.patching') as patchingValue,
(SELECT VALUE FROM ORDS_METADATA.USER_ORDS_PROPERTIES WHERE KEY = 'plsql.gateway.version') as versionValue
FROM dual]';
BEGIN
BEGIN
EXECUTE IMMEDIATE GATEWAY_DETAILS INTO L_PATCH, L_VERSION;
EXCEPTION
WHEN OTHERS THEN
-- ignore exception and leave l_patch as null so fallback is executed
NULL;
END;
IF L_PATCH IS NULL THEN
-- L_PATCH IS NULL, EITHER AN OLDER VERSION OF APEX IS PRESENT OR APEX IS NOT INSTALLED
-- CHECK IF APEX PRESENT
DECLARE
L_SQL VARCHAR2(200) := 'select patch_applied from apex_release';
BEGIN
DBMS_UTILITY.NAME_RESOLVE('APEX_RELEASE', 0, SCHEMA, PART1, PART2, DBLINK, PART1_TYPE, OBJECT_NUM);
EXECUTE IMMEDIATE L_SQL INTO L_PATCH;
EXCEPTION
WHEN OTHERS THEN
-- Could not access apex_release. Default l_patch to 'N' so it's still served
L_PATCH :='N';
END;
END IF;
END;
:4 := L_PATCH;
:5 :=L_VERSION;
END;The flag that tells ORDS that APEX is currently being patched has been moved to ORDS_METADATA schema. And in my case the query indeed returned TRUE.
SELECT VALUE FROM ORDS_METADATA.USER_ORDS_PROPERTIES WHERE KEY = 'plsql.gateway.patching'After flipping it to FALSE, downgraded APEX started working again.
UPDATE ORDS_METADATA.USER_ORDS_PROPERTIES set value='FALSE' WHERE KEY = 'plsql.gateway.patching';- Written by: ilmarkerm
- Category: Blog entry
- Published: July 29, 2024
We are refreshing development databases from production using storage thin cloning. Everything works automatically and part of refresh procedure is also running some SQLPlus scripts, using OS authentication, as SYS.
One database also has APEX, that uses APEX Social Login feature to give users single sign-on for both APEX Builder and the end user application. You can read here how to set it up using Azure SSO. But since APEX is fully inside the database, this means that the production SSO credentials get copied over during database refresh.
I would like to have a SQL script that would run as part of the database refresh procedure, that would replace the APEX SSO credentials. And I’d like that script to run as SYS.
- Written by: ilmarkerm
- Category: Blog entry
- Published: July 18, 2024
We have been using Single-Sign On for APEX applications for a long time, way before there was social login feature available in APEX itself. We implemented it on web server level in front of APEX. But in order to simplify the webserver setup (mainly to disable sticky load balancer setup) and since APEX for quite some time can do some SSO protocols now internally – we finally moved to APEX social sign-in – using OpenID connector. I blogged about it here earlier.
Enabled it last evening, everything worked fine over night (low use), and suddenly, this morning, when the real use begins, application users started getting the following login failures:
The HTTP request to “https://login.microsoftonline.com/<tenancy_id>/v2.0/.well-known/openid-configuration” failed.
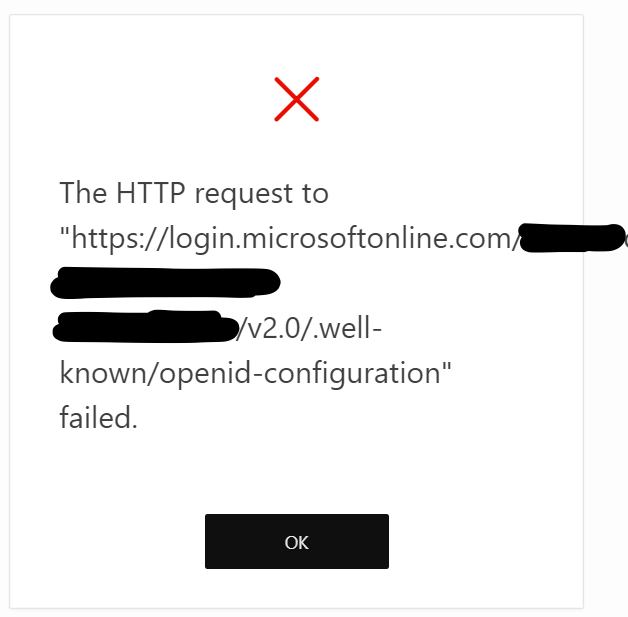
Quite un-informative… why did it fail? This URL is the OpenID discovery URL and the message comes from APEX, not Azure SSO. A few quick checks:
- The URL works, and it returns proper 200 OK status code, even from the database server
- If there were any TLS errors, then the error message would be different
- No new messages in APEX_DEBUG_MESSAGES since the issue started
- Nothing in APEX_WEBSERVICE_LOG
- Nothing in alert.log 🤔
- Changing APEX instance proxy did not help
- TLS wallet was accessible and good
- The error is returned ONLY to application users, even though builder uses the same OpenID Discovery URL – and APEX builder login works without any issues
- And every developer swore, that noone has changed anything today
As a side-note – the end-user applications are quite heavily used and there are hundreds of internal users.
Finally I started creating new Authentications scheme using Generic OAuth2 instead and they seemed to connect to Azure services without issues. But then messages started appearing in APEX_DEBUG_MESSAGES (what triggered that DEBUG logging started writing? accessing applications via Builder?) and hidden deep in messages I found the gem:
Exception in "GET https://login.microsoftonline.com/azure_tenancy_id/v2.0/.well-known/openid-configuration":
Error Stack: ORA-20001: You have exceeded the maximum number of web service requests per workspace. Please contact your administrator.Looks like, at least in APEX 23.1, calls to OpenID discovery URL count towards the APEX workspace web service request limiter, after increasing the limit the authentication started working again.
exec APEX_INSTANCE_ADMIN.SET_PARAMETER('MAX_WEBSERVICE_REQUESTS', 100000);Problem solved, but it was quite confusing to troubleshoot due to lack of more detailed error messages. I really do not expect authentication hitting a rate limiter and then being completely silent about the underlying cause.