- Written by: ilmarkerm
- Category: Blog entry
- Published: May 12, 2023
We have hundreds of developers who need access hundreds of application schemas, deployed to multiple locations. Data is sensitive and there is a requirement that each human access must be done via a personal database account that has access to only allowed application schemas. That has always been a struggle for me how to manage all these access privileges in a nice and easy way. Since many many many different databases are involved, database itself cannot be the source of truth for the access privileges and so far we have just synchronised the access privileges from the source of truth system to all individual databases.
I think there is a better way now – Secure Application Roles.
The idea behind them is very flexible – there is no need to grant the individual roles to database users, the users need to execute a procedure (which will do all necessary validations) and then enable the role(s) for the user session.
Lets first set up a common SECURITY_MANAGER schema, that will contain all our security related code and logging.
create user security_manager no authentication
default tablespace users
quota 1g on users;
grant create table, create procedure to security_manager;
create table security_manager.allowed_grants (
db_username varchar2(128) not null,
db_role varchar2(128) not null,
primary key (db_username,db_role)
) organization index;
create table security_manager.role_grant_log (
grant_time timestamp default sys_extract_utc(systimestamp) not null,
db_username varchar2(128) not null,
granted_role varchar2(128) not null,
is_allowed number(1) not null,
comments varchar2(1000),
client_host varchar2(200),
client_ip varchar2(50),
unified_audit_session_id varchar2(100)
);Here are two helper programs, since ACTIVATE_ROLE procedure below will need to read and write to tables in SECURITY_MANAGER schema and I do not want to grant access to these tables to users directly.
-- The job of the following procedure is just logging the grant request
CREATE OR REPLACE PROCEDURE security_manager.log_role_grant
(p_requested_role role_grant_log.granted_role%TYPE
, p_is_allowed role_grant_log.is_allowed%TYPE
, p_comments role_grant_log.comments%TYPE)
ACCESSIBLE BY (activate_role) IS
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
INSERT INTO role_grant_log
(db_username, granted_role, is_allowed, comments
, client_host, client_ip, unified_audit_session_id)
VALUES
(SYS_CONTEXT('USERENV','SESSION_USER')
, p_requested_role, p_is_allowed, SYS_CONTEXT('USERENV','HOST')
, SYS_CONTEXT('USERENV','IP_ADDRESS')
, SYS_CONTEXT('USERENV','UNIFIED_AUDIT_SESSIONID'));
COMMIT;
END;
/
-- The following function just check the master autorisation table if
-- user is allowed to activate the role or not
CREATE OR REPLACE FUNCTION security_manager.is_role_allowed
(p_username allowed_grants.db_username%TYPE
, p_requested_role role_grant_log.granted_role%TYPE) RETURN boolean
ACCESSIBLE BY (activate_role) IS
v_is_role_allowed NUMBER;
BEGIN
SELECT COUNT(*) INTO v_is_role_allowed
FROM allowed_grants
WHERE db_username = p_username AND db_role = UPPER(p_requested_role);
RETURN v_is_role_allowed = 1;
END;
/Now the security code itself. The procedure below just checks from a simple table, if the logged in user is allowed to activate the requested role or not and also logs the request. In real life it can be much more complex – the code could make a REST call to external autorisation system and ofcourse logging should be much more detailed.
NB! The procedure must be declared AUTHID CURRENT_USER – using invokers rights.
CREATE OR REPLACE PROCEDURE security_manager.activate_role
(p_requested_role allowed_grants.db_role%TYPE
, p_comments role_grant_log.comments%TYPE)
AUTHID CURRENT_USER IS
v_activated_roles VARCHAR2(4000);
BEGIN
-- Check if users is allowd to activate the requested role
IF NOT is_role_allowed(SYS_CONTEXT('USERENV','SESSION_USER'), p_requested_role) THEN
log_role_grant(upper(p_requested_role), 0, p_comments);
raise_application_error(-20000, 'You are not allowed to activate the requested role.');
END IF;
-- Query all roles that are currently active for the session and append the requested role to that list
SELECT listagg(role, ',') WITHIN GROUP (ORDER BY role) INTO v_activated_roles FROM (
SELECT role FROM session_roles
UNION
SELECT upper(p_requested_role) FROM dual
);
-- Activate all roles
log_role_grant(upper(p_requested_role), 1, p_comments);
DBMS_SESSION.SET_ROLE(v_activated_roles);
END;
/Now I create the role itself and grant the role read access to one application table. Here IDENTIFIED USING clause does the magic – it tells Oracle that sec_app_role_test1 role can only be enabled by security_manager.activate_role procedure.
CREATE ROLE sec_app_role_test1
IDENTIFIED USING security_manager.activate_role;
GRANT READ ON app1.t1 TO sec_app_role_test1;And my developer personal account is called ILMKER and this account only needs execute privileges on my security package. In real life you would grant this execute to a common role that all developers have (in my case that custom role is called PERSONAL_ACCOUNT).
GRANT execute ON security_manager.activate_role TO ilmker;By default ILMKER user cannot access table APP1.T1.
ILMKER SQL> SELECT * FROM session_roles;
ROLE
-----------------
PERSONAL_ACCOUNT
ILMKER SQL> SELECT * FROM app1.t1;
SQL Error: ORA-00942: table or view does not existLets test using my developer account ILMKER… first I try to request a role that I do not have been granted access to. No luck, I get the exception “ORA-20000: You are not allowed to activate the requested role.”
SQL> SELECT * FROM session_roles;
ROLE
--------------------
PERSONAL_ACCOUNT
SQL> exec security_manager.activate_role('sec_app_role_test1', 'Jira ref: ABC-490');
ORA-20000: You are not allowed to activate the requested role.
SQL> SELECT * FROM session_roles;
ROLE
--------------------
PERSONAL_ACCOUNT
SQL> SELECT * FROM app1.t1;
SQL Error: ORA-00942: table or view does not existAfter security administrator grants me the role – inserts a row to security_manager.allowed_grants table for this example and NOT executing Oracle GRANT command.
insert into security_manager.allowed_grants (db_username, db_role)
values ('ILMKER', upper('sec_app_role_test1'));
commit;I ask my developer to run again.
SQL> SELECT * FROM session_roles;
ROLE
--------------------
PERSONAL_ACCOUNT
SQL> exec security_manager.activate_role('sec_app_role_test1', 'Jira ref: ABC-490');
PL/SQL procedure successfully completed.
SQL> SELECT * FROM session_roles;
ROLE
--------------------
PERSONAL_ACCOUNT
SEC_APP_ROLE_TEST1
SQL> SELECT * FROM app1.t1;
no rows selectedThe developer is happy now! Role was activated in the developer session and developer was able to read the application table. All requests were also logged by SECURITY_MANAGER schema.
SQL> select * from security_manager.role_grant_log; GRANT_TIME DB_USERNAME GRANTED_ROLE CLIENT_HOST CLIENT_IP UNIFIED_AUDIT_SESSION_ID IS_ALLOWED COMMENTS 2023-05-12 15:05:28,478732000 ILMKER SEC_APP_ROLE_TEST1 STH-FVFFV04QQ05R 10.88.17.241 3428220339 0 Jira ref: ABC-490 2023-05-12 15:10:41,923908000 ILMKER SEC_APP_ROLE_TEST1 STH-FVFFV04QQ05R 10.88.17.241 3428220339 1 Jira ref: ABC-490
I think this is a powerful feature to control access to data based on much more complex criteria than just DBA executing GRANT commands. Before enabling the role code can make a REST query to external autorisation system, check the client host IP, check the client authentication method, enable detailed unified auditing policies. Possibilities are endless!
- Written by: ilmarkerm
- Category: Blog entry
- Published: March 18, 2023
It feels like no-one is really talking about running Oracle database on a filesystem for years now. ASM seems to be the way to go. Oracle in the documentation even says that local file systems, although supported, are not recommended.
ASM works great and if you have RAC or a few dear pet databases, ASM for sure is a safe way to go – no argument from me here at all. I especially love the possibility to mirror the storage between different failure goups, that are defined by the administrator, so you can mirror the storage lets say between different hardware racks or availability zones or just different storage hardware. For high-end dear pet setups, ASM is no doubt the only way to go.
But I think the story changes for large cattle of small cloudy databases, where you have a large number of databases and you want to spend minimal effort managing a single one. After Oracle removed ASM from the database installation in 11g, now ASM requires Oracle Grid Infrastructure (Oracle Restart) installation – a separate Oracle software setup – that is, as any Oracle software, notoriously hard to maintain, patch – compared to standard Linux software. And the performance benefits promised by ASM, async IO and direct IO, are also available on a file system. True – the choice of filesystems and setups is harder to manage, but if you do your testing properly, the end result is easier to maintain. Do keep in mind, Oracle does not test running on filesystems any more and any problem is left to the OS support to resolve – which in case of using Oracle Linux, is also Oracle 🙂
There are many historical blogs about running Oracle on filesystems in the Internet, and the consensus seems to be that XFS is the best filesystem currently for running databases.
In addition, note Oracle Linux: Supported and Recommended File Systems (Doc ID 236826.1) also says this about XFS:
XFS is designed for high scalability and provides near native I/O performance even when the file system spans multiple storage devices. Beginning with Oracle Linux 7, XFS is the default file system and is included with Basic and Premier Support subscriptions, at no additional charge.
Based on this information I’ve been running my cattle on custom cloud small database instances on XFS, but quite soon started to have complaints about occasional database slowness and observed high log file sync and commit times. The important bit here – the applications in question commit a lot – they are micro/mini-services that get called a lot. Like many thousands of times per second. Before during platform testing I wasn’t really able to see any such behaviour, because i used tools like Swingbench and SLOB – and they are quite well behaved apps.
Then by accident found a post in Redhat support portal:
https://access.redhat.com/solutions/5906661
That rather recently XFS maintainers introduced a change, that non-aligned (to filesystem block size) direct IO write requests get serialized more thoroughly now. That change was introduced on purpose to avoid possible corruptions.
The change itself is here. It is just intorucing some extra waits on XFS filesystem level.
https://lore.kernel.org/linux-xfs/e2d4678c-eeae-e9df-dde7-84601a52d903@oracle.com/
By default XFS uses 4096 byte block size – so unless you use 4096 blocksize for Oracle redo logs – you will hit this issue. Using 512 block size redo logs on 4096 block size XFS filesystem, means Oracle will issue non-aligned writes for redo.
On Linux Oracle allows setting redo log block size to either 512 or 4096 bytes, but it has a protection mechanism – the redo log block size must match the storage physical sector size. Quoting from Doc ID 2148290.1.
Using 512N disks as 4K leads to atomicity problem (e.g. ASM/DB write operation thinks that 4K IO size is atomic which is not. It leads to consistency issues when there is a crash in the middle of a 4K write causing partial write).
If you use 512 sector size disks, then Oracle will allow you to only create redo logs with 512 byte blocksize.
# cat /sys/block/vdf/queue/physical_block_size
512
# cat /sys/block/vdf/queue/logical_block_size
512
SQL> alter database add logfile '/oralocal/1.rdo' size 1g blocksize 4096;
ORA-01378: The logical block size (4096) of file /oralocal/1.rdo is not
compatible with the disk sector size (media sector size is 512 and host sector size is 512)If you want to use XFS for redo logs, you need to create XFS filesystem with 512 byte block size. This bring another issue – XFS has deprecated this small block size. It is still currently possible, but warning is issued.
# mkfs.xfs -b size=512 -m crc=0 -f /dev/vg01/redo
V4 filesystems are deprecated and will not be supported by future versions.
meta-data=/dev/vg01/redo isize=256 agcount=4, agsize=31457280 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0, sparse=0, rmapbt=0
= reflink=0 bigtime=0 inobtcount=0
data = bsize=512 blocks=125829120, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=512 blocks=204800, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0To me this brings the following conclusions:
- XFS can only be used for Oracle redo logs if you use storage with 4096 sector size (advanced format)
- For 512 byte sector size storage, a different filesystem is needed. For example EXT4.
- XFS is still fine to use for Oracle datafiles. This issue only concerns redo.
Testing the impact
How bad this issue is exactly. When I ran comparisons using SLOB, I did not notice the difference betwen XFS and EXT4 much. Looking at the storage patterns I saw that SLOB issues large writes and commits rarely, so storage sees quite large writes coming from the log writer.
But my apps make small changes and commit crazy often (yes, bad database application desgn – but I think quite common thinking for an average enterprise application developer). So I needed a new testing suite that can generate high number of IOPS with very small IO sizes. Introducting Horrible Little Oracle Benchmark.
https://gist.github.com/ilmarkerm/462d14da050fb73fb4eeed5384604f1b
This just commits a lot, after making a small change to the database. The results below do not represent any kind of maximum throughput limits, I just wanted to see the impact of using different filesystems under similar load.
Baseline… XFS bsize=4096
Load Profile Per Second Per Transaction
~~~~~~~~~~~~~~~ --------------- ---------------
Redo size (bytes): 2,247,197.7 573.7
Logical read (blocks): 19,760.3 5.0
Block changes: 15,744.3 4.0
Physical read (blocks): 0.3 0.0
Physical write (blocks): 45.6 0.0
Read IO requests: 0.3 0.0
Write IO requests: 3.6 0.0
Executes (SQL): 3,923.7 1.0
Transactions: 3,917.3
Event Waits Time (sec) Wait time
------------------------------ ----------- ---------- --------- ------
log file sync 2,367,110 3340.7 1.41ms 92.8
DB CPU 281.9 7.8
buffer busy waits 129,582 4.6 35.49us .1
log file switch (private stran 10 .1 9.29ms .0
db file sequential read 122 .1 513.16us .0
control file sequential read 98 0 327.92us .0
Total
%Time Wait Waits % bg
Event Waits -outs Time (s) Avg wait /txn time
-------------------------- ----------- ----- -------- --------- -------- ------
log file parallel write 1,182,647 0 1,166 .99ms 0.5 64.6
LGWR any worker group 1,179,342 0 592 501.58us 0.5 32.8
EXT4
Load Profile Per Second Per Transaction
~~~~~~~~~~~~~~~ --------------- ---------------
Redo size (bytes): 4,151,622.2 571.5
Executes (SQL): 7,267.6 1.0
Transactions: 7,264.7
Event Waits Time (sec) Wait time
------------------------------ ----------- ---------- --------- ------
log file sync 4,386,595 3114.6 710.03us 86.5
DB CPU 517.8 14.4
buffer busy waits 302,823 11.1 36.71us .3
Total
%Time Wait Waits % bg
Event Waits -outs Time (s) Avg wait /txn time
-------------------------- ----------- ----- -------- --------- -------- ------
log file parallel write 1,954,831 0 841 430.21us 0.4 59.8
LGWR any worker group 1,226,037 0 271 221.22us 0.3 19.3
LGWR all worker groups 330,590 0 166 502.00us 0.1 11.8
LGWR worker group ordering 318,164 0 47 146.44us 0.1 3.3
XFS with blocksize 512
Load Profile Per Second Per Transaction
~~~~~~~~~~~~~~~ --------------- ---------------
Redo size (bytes): 4,118,949.8 571.4
Executes (SQL): 7,213.7 1.0
Transactions: 7,208.6
Event Waits Time (sec) Wait time
------------------------------ ----------- ---------- --------- ------
log file sync 4,354,303 3127.9 718.34us 86.9
DB CPU 503.7 14.0
buffer busy waits 349,311 12.5 35.76us .3
Total
%Time Wait Waits % bg
Event Waits -outs Time (s) Avg wait /txn time
-------------------------- ----------- ----- -------- --------- -------- ------
log file parallel write 1,950,597 0 847 434.01us 0.4 59.7
LGWR any worker group 1,245,012 0 277 222.65us 0.3 19.5
LGWR all worker groups 330,132 0 169 512.99us 0.1 11.9
LGWR worker group ordering 318,918 0 44 139.26us 0.1 3.1
EXT4 with LVM
On previous tests I created file system on top of the raw block device, here I want to compare what happens if there is LVM in the middle.
Load Profile Per Second Per Transaction
~~~~~~~~~~~~~~~ --------------- ---------------
Redo size (bytes): 3,412,249.5 571.3
Executes (SQL): 5,981.8 1.0
Transactions: 5,972.8
Event Waits Time (sec) Wait time
------------------------------ ----------- ---------- --------- ------
log file sync 3,613,132 3203.5 886.64us 88.9
DB CPU 423.9 11.8
buffer busy waits 301,471 11 36.60us .3
Total
%Time Wait Waits % bg
Event Waits -outs Time (s) Avg wait /txn time
-------------------------- ----------- ----- -------- --------- -------- ------
log file parallel write 1,610,090 0 843 523.49us 0.4 59.0
LGWR any worker group 1,024,262 0 280 273.01us 0.3 19.6
LGWR all worker groups 270,089 0 171 631.60us 0.1 11.9
LGWR worker group ordering 310,863 0 66 210.95us 0.1 4.6
The important bits
- Oracle RDBMS 19.16.2
- Oracle Linux 8.7 with UEKr6 kernel 5.4.17-2136.316.7.el8uek.x86_64
- Dedicated filesystem for redo logs
- filesystemio_options=setall
- No partitioning on block devices
During all tests datafiles remained at the same filesystem and the load on them was absolutely minimal. Between each test I reformatted the redo log filesystem and copied the redo log files over to the new filesystem.
I also tested both XFS and EXT4 when filesystemio_options set to asynch or none, but both of them performed similarly to XFS bsize=4096 with filesystemio_options=setall.
Conclusion
From my tests I conclude, that XFS performance degradation (when not using 4096 byte sector size storage) for high-commit rate applications is significant. The slowdown is observed as longer latency in log file sync and log file parallel write wait events.
As a replacement, EXT4 and XFS blocksize=512 perform similarly. Adding LVM in the mix, reduces the commit throughput a little. Since XFS blocksize=512 is deprecated, EXT4 is the go-to major filesystem on Linux for Oracle database redo logs.
Before going for a file system for Oracle database, do read through Oracle Linux: Supported and Recommended File Systems (Doc ID 236826.1) to understand the implications.
- Written by: ilmarkerm
- Category: Blog entry
- Published: March 11, 2023
Here is a list of things that I think are important to monitor if you have Data Guard FSFO setup. All the mentioned things are intended for automated monitoring – things to raise alerts on.
My goal is to get as much information as possible from one place – the primary database. Since the primary database is alwas open and you can always connect your monitoring agent there.
This is about Oracle 19c (19.16.2 at the time of writing).
Here I’m also assuming Data Guard protection mode is set to MaxAvailability (or MaxProtection).
The overall status of Data Guard broker
I think the best way to get a quick overview of Data Guard health is to query V$DG_BROKER_CONFIG. It can be done from primary and it gives you a quick status for each destination.
SYS @ failtesti2:>SELECT database, dataguard_role, enabled, status
FROM V$DG_BROKER_CONFIG;
DATABASE DATAGUARD_ROLE ENABL STATUS
------------ ------------------ ----- ----------
failtesti1 PHYSICAL STANDBY TRUE 0
failtesti2 PRIMARY TRUE 0
failtesti3 PHYSICAL STANDBY TRUE 16809STATUS column is the most interesting. It gives you the current ORA error code for this destination. If it is 0 – ORA-0 means “normal, successful completion”.
Is FSFO target SYNCHRONIZED?
In case Fast-Start Failover is enabled – you need to be alerted if the FSFO target becomes UNSYNCHRONIZED. You can query it from V$DATABASE.
SYS @ failtesti2:>SELECT FS_FAILOVER_MODE, FS_FAILOVER_STATUS, FS_FAILOVER_CURRENT_TARGET, FS_FAILOVER_THRESHOLD
FROM V$DATABASE;
FS_FAILOVER_MODE FS_FAILOVER_STATUS FS_FAILOVER_CURRENT_TARGET FS_FAILOVER_THRESHOLD
------------------- ---------------------- ------------------------------ ---------------------
ZERO DATA LOSS SYNCHRONIZED failtesti1 25
-- After bouncing failtesti1
SYS @ failtesti2:>SELECT FS_FAILOVER_MODE, FS_FAILOVER_STATUS, FS_FAILOVER_CURRENT_TARGET, FS_FAILOVER_THRESHOLD
FROM V$DATABASE;
FS_FAILOVER_MODE FS_FAILOVER_STATUS FS_FAILOVER_CURRENT_TARGET FS_FAILOVER_THRESHOLD
------------------- ---------------------- ------------------------------ ---------------------
ZERO DATA LOSS UNSYNCHRONIZED failtesti1 25Alert if FS_FAILOVER_STATUS has been UNSYNCHRONIZED for too long.
Is Observer connected?
In FSFO you also need to alert if observer is no longer present. If there is no observer, FSFO will not happen and you also loose quorum. If both standby database and observer are down – primary databases loses quorum and also shuts down.
Again, you can query V$DATABASE from the primary database.
SYS @ failtesti2:>SELECT FS_FAILOVER_MODE, FS_FAILOVER_CURRENT_TARGET, FS_FAILOVER_OBSERVER_PRESENT, FS_FAILOVER_OBSERVER_HOST
FROM V$DATABASE;
FS_FAILOVER_MODE FS_FAILOVER_CURRENT_TARGET FS_FAIL FS_FAILOVER_OBSERVER_HOST
------------------- ------------------------------ ------- ------------------------------
ZERO DATA LOSS failtesti1 YES failtest-observer
-- After stopping the observer
SYS @ failtesti2:>SELECT FS_FAILOVER_MODE, FS_FAILOVER_CURRENT_TARGET, FS_FAILOVER_OBSERVER_PRESENT
FROM V$DATABASE;
FS_FAILOVER_MODE FS_FAILOVER_CURRENT_TARGET FS_FAIL
------------------- ------------------------------ -------
ZERO DATA LOSS failtesti1 NOAlert if FS_FAILOVER_OBSERVER_PRESENT has been NO for too long.
Is the protection mode as intended?
Good to monitor to avoid DBA human errors. Maybe a DBA lowered the protection mode and forgot to reset it back to the original value. Again this information is available on V$DATABASE. Probably not needed, but it is an easy and check check.
SYS @ failtesti2:>SELECT PROTECTION_MODE, PROTECTION_LEVEL
FROM V$DATABASE;
PROTECTION_MODE PROTECTION_LEVEL
-------------------- --------------------
MAXIMUM AVAILABILITY MAXIMUM AVAILABILITYMonitoring Apply and Transport lag
Probably this is one of the most asked about things to monitor about Data Guard. And the obvious way to do it is via Data Guard Broker.
First – you have ApplyLagThreshold and TransportLagThreshold properties for each database and if that is breached, Data Guard Broker will raise an alarm – the database status will change.
-- On my standby database I have ApplyLagThreshold and TransportLagThreshold set
DGMGRL> show database failtesti3 ApplyLagThreshold;
ApplyLagThreshold = '30'
DGMGRL> show database failtesti3 TransportLagThreshold;
TransportLagThreshold = '30'
-- I do breach both of the thresholds
DGMGRL> show database failtesti3;
Database - failtesti3
Role: PHYSICAL STANDBY
Intended State: APPLY-ON
Transport Lag: 1 minute 38 seconds (computed 49 seconds ago)
Apply Lag: 1 minute 38 seconds (computed 49 seconds ago)
Average Apply Rate: 6.00 KByte/s
Real Time Query: ON
Instance(s):
failtesti3
Database Warning(s):
ORA-16853: apply lag has exceeded specified threshold
ORA-16855: transport lag has exceeded specified threshold
ORA-16857: member disconnected from redo source for longer than specified threshold
Database Status:
WARNING
-- If I query V$DG_BROKER_CONFIG from PRIMARY the status reflects that
SYS @ failtesti2:>SELECT database, dataguard_role, status
FROM V$DG_BROKER_CONFIG;
DATABASE DATAGUARD_ROLE STATUS
--------------- ------------------ ----------
failtesti1 PHYSICAL STANDBY 0
failtesti2 PRIMARY 0
failtesti3 PHYSICAL STANDBY 16809
$ oerr ora 16809
16809, 00000, "multiple warnings detected for the member"
// *Cause: The broker detected multiple warnings for the member.
// *Action: To get a detailed status report, check the status of the member
// specified using either Enterprise Manager or the DGMGRL CLI SHOW
// command.
-- If I fix the transport lag
SYS @ failtesti2:>SELECT database, dataguard_role, status
FROM V$DG_BROKER_CONFIG;
DATABASE DATAGUARD_ROLE STATUS
--------------- ------------------ ----------
failtesti1 PHYSICAL STANDBY 0
failtesti2 PRIMARY 0
failtesti3 PHYSICAL STANDBY 16853
$ oerr ora 16853
16853,0000, "apply lag has exceeded specified threshold"
// *Cause: The current apply lag exceeded the value specified by the
// ApplyLagThreshold configurable property. It may be caused either by
// a large transport lag or poor performance of apply services on the
// standby database.
// *Action: Check for gaps on the standby database. If no gap is present, tune
// the apply services.Really good for monitoring and the monitoring agent only needs to connect to the primary database. If status != 0, we have a problem.
OK good, but that will only tell you that the threshold was breached – but how big is the lag actually? Managers like charts. If you can query from standby database, V$DATAGUARD_STATS is your friend.
-- Has to be executed from standby database
WITH
FUNCTION interval_to_seconds(p_int interval day to second) RETURN number
DETERMINISTIC
IS
BEGIN
-- Converts interval to seconds
RETURN
extract(day from p_int)*86400+
extract(hour from p_int)*3600+
extract(minute from p_int)*60+
extract(second from p_int);
END;
SELECT name, interval_to_seconds(to_dsinterval(value)) lag_s
FROM v$dataguard_stats
WHERE name IN ('transport lag','apply lag')Another view to get more details about the apply process is V$RECOVERY_PROGRESS. Again have to query it from the standby database itself. You can see apply rates for example from there.
What if you can not (do not want to) connect to (each) standby database, maybe it is in MOUNTED mode (I object to connecting remotely as SYS)? How to get standby lag querying from primary database?
Documented option is to query V$ARCHIVE_DEST, not great and does not work for cascaded destinations.
SYS @ failtesti2:>SELECT dest_id, dest_name, applied_scn, scn_to_timestamp(applied_scn)
FROM v$archive_dest
WHERE status = 'VALID' and applied_scn > 0;
DEST_ID DEST_NAME APPLIED_SCN SCN_TO_TIMESTAMP(APPLIED_SCN)
---------- -------------------- ----------- -----------------------------
2 LOG_ARCHIVE_DEST_2 409036447 2023-03-11 07:40:00
3 LOG_ARCHIVE_DEST_3 409173280 2023-03-11 07:41:27Not really great for monitoring.
Is there a possibility to query Broker data from primary database? Currently not in a documented way.
-- Query from Broker. NB! DBMS_DRS is currently undocumented.
-- X$DRC is X$, so it will never be documented, and you can only query it as SYS/SYSDG.
SYS @ failtesti2:>SELECT value database_name, dbms_drs.get_property_obj(object_id, 'ApplyLag') apply_lag
FROM x$drc
WHERE attribute='DATABASE' and value != 'failtesti2';
DATABASE_NAM APPLY_LAG
------------ ------------
failtesti1 0 0
failtesti3 1174 40
-- As a comparison
SYS @ failtesti2:>SELECT dest_id, dest_name, applied_scn, cast(systimestamp as timestamp) - scn_to_timestamp(applied_scn) lag
FROM v$archive_dest
WHERE status = 'VALID' and applied_scn > 0;
DEST_ID DEST_NAME APPLIED_SCN LAG
---------- -------------------- ----------- ------------------------------
2 LOG_ARCHIVE_DEST_2 409036447 +000000000 00:20:13.863936000
3 LOG_ARCHIVE_DEST_3 411005382 +000000000 00:00:40.863936000
-- Comparing these numbers it seems to me that "1174 40" should be interpreted as "lag_in_seconds measurement_age_in_seconds"
-- So failtesti3 had 1174 seconds of lag measured 40 seconds ago
-- The same also works for TransportLag
SYS @ failtesti2:>SELECT value database_name, dbms_drs.get_property_obj(object_id, 'TransportLag') transport_lag
FROM x$drc
WHERE attribute='DATABASE' and value != 'failtesti2';
DATABASE_NAM TRANSPORT_LAG
------------ -------------
failtesti1 0 0
failtesti3 107 56Also – my favourite actually – if you have Active Data Guard licence and the standby is open – just have a pinger job in primary database updating a row every minute (or 30s??) to the current UTC timestamp sys_extract_utc(systimestamp). And have your monitoring agent check on the standby side how old that timestamp is. It is my favourite, because it is a true end-to-end check, it does not depend on any dark unseen Data Guard inner workings and wonderings if the reported numbers by Broker are correct.
Is MRP running (the apply process)?
Monitoring lag via Broker is great, but if by DBA accident you set APPLY-OFF for a maintenance – and forget to start it again. Since administrator has told Broker that APPLY should be OFF, Broker will not raise ApplyLag warnings anymore. So if Failover happens – it will be very slow, since it also needs to apply all the missing logs.
-- To demonstrate the problem
DGMGRL> show database failtesti3 ApplyLagThreshold;
ApplyLagThreshold = '30'
-- ApplyLagThreshold is 30s and current Apply Lag is 25 min, but status is SUCCESS!
-- This is because Intended State: APPLY-OFF
DGMGRL> show database failtesti3;
Database - failtesti3
Role: PHYSICAL STANDBY
Intended State: APPLY-OFF
Transport Lag: 0 seconds (computed 1 second ago)
Apply Lag: 25 minutes 3 seconds (computed 1 second ago)
Average Apply Rate: (unknown)
Real Time Query: OFF
Instance(s):
failtesti3
Database Status:
SUCCESS
-- Same from primary, failtesti3 has status=0
SYS @ failtesti2:> SELECT database, dataguard_role, enabled, status
FROM V$DG_BROKER_CONFIG;
DATABASE DATAGUARD_ROLE ENABL STATUS
------------ ------------------ ----- ----------
failtesti1 PHYSICAL STANDBY TRUE 0
failtesti2 PRIMARY TRUE 0
failtesti3 PHYSICAL STANDBY TRUE 0
-- Sure will still show Apply Lag from Broker
SYS @ failtesti2:> SELECT value database_name, dbms_drs.get_property_obj(object_id, 'ApplyLag') apply_lag
FROM x$drc
WHERE attribute='DATABASE' and value = 'failtesti3';
DATABASE_NAM APPLY_LAG
------------ ------------
failtesti3 1792 0How to check that all targets are applying? One option is to actually check on standby side, if MRP0 process is running.
SYS @ failtesti3:>SELECT process
FROM V$MANAGED_STANDBY
WHERE process = 'MRP0';
PROCESS
---------
MRP0
-- I shut down apply
DGMGRL> edit database failtesti3 set state='apply-off';
Succeeded.
-- No MRP0 anymore
SYS @ failtesti3:>SELECT process FROM V$MANAGED_STANDBY WHERE process = 'MRP0';
no rows selectedBut for automated monitoring I don’t really like to connect to each standby, especially if no Active Data Guard is in use. How to get it from primary? It gets a little tricky.
-- To check the intended state, could also go for the unsupported route.
-- APPLY-READY means APPLY-OFF
SYS @ failtesti2:>SELECT value database_name, dbms_drs.get_property_obj(object_id, 'intended_state') intended_state
FROM x$drc
WHERE attribute='DATABASE' and value = 'failtesti3';
DATABASE_NAM INTENDED_STATE
------------ --------------------
failtesti3 PHYSICAL-APPLY-READY
-- After turning APPLY-ON
DGMGRL> edit database failtesti3 set state='apply-on';
Succeeded.
SYS @ failtesti2:>SELECT value database_name, dbms_drs.get_property_obj(object_id, 'intended_state') intended_state
FROM x$drc
WHERE attribute='DATABASE' and value = 'failtesti3';
DATABASE_NAM INTENDED_STATE
------------ --------------------
failtesti3 PHYSICAL-APPLY-ONHere could check that Broker has the intended state correct for all standby databases.
Broker also has export configuration option, that could possibly be used for some automated checks. It is a documented DGMGRL command, but the resulting XML file is placed under database trace directory and the contents of that XML file are not documented.
[oracle@failtest-2 ~]$ dgmgrl / "export configuration to auto-dg-check.xml"
DGMGRL for Linux: Release 19.0.0.0.0 - Production on Sat Mar 11 09:04:17 2023
Version 19.16.2.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
Welcome to DGMGRL, type "help" for information.
Connected to "FAILTESTI2"
Connected as SYSDG.
Succeeded.
-- The result is an XML file with all interesting Broker configurations that could be used for automated monitoring
[oracle@failtest-2 ~]$ cat /u01/app/oracle/diag/rdbms/failtesti2/failtesti2/trace/auto-dg-check.xml
...
<Member MemberID="1" CurrentPath="True" Enabled="True" MultiInstanced="True" Name="failtesti1">
<DefaultState>STANDBY</DefaultState>
<IntendedState>STANDBY</IntendedState>
<Status>
<Severity>Success</Severity>
<Error>0</Error>
<Timestamp>1678525406</Timestamp>
</Status>
<Role>
<Condition>STANDBY</Condition>
<DefaultState>PHYSICAL-APPLY-ON</DefaultState>
<IntendedState>PHYSICAL-APPLY-ON</IntendedState>
</Role>
...
</Member>
...
<Member MemberID="3" CurrentPath="True" Enabled="True" MultiInstanced="True" Name="failtesti3">
<Status>
<Severity>Success</Severity>
<Error>0</Error>
<Timestamp>1678525396</Timestamp>
</Status>
<Role>
<Condition>STANDBY</Condition>
<DefaultState>PHYSICAL-APPLY-ON</DefaultState>
<IntendedState>PHYSICAL-APPLY-READY</IntendedState>
</Role>
...
</Member>
...Recovery Area
Need to cover also the basics – like Recovery Area usage. When using Data Guard you have most likely set ArchivelogDeletionPolicy to Applied On (All) Standby… or shipped, so if any of the standby databases fall behind, the recovery are on primary (or other standby databases) will also start to grow. Keep an eye on that.
Useful views: V$RECOVERY_FILE_DEST (or V$RECOVERY_AREA_USAGE to see the breakdown into individual consumers).
SELECT sys_extract_utc(systimestamp) time
, name recovery_dest_location
, round(space_limit/1024/1024/1024) size_gb
, round((space_used-space_reclaimable)/1024/1024/1024) used_gib
, round((space_used-space_reclaimable)*100/space_limit) used_pct
FROM V$RECOVERY_FILE_DESTConnecting to the alert.log topic below… if you have been slow to react on the proactive recovery area check above, always good to keep mining alert.log for ORA-19809. If that is seen, raise the highest immediate alert – recovery area is full and archiving is stopped.
Alert.log
Always a good idea to keep an eye on important messages from alert.log even if they are not directly related to Data Guard. I’ve blogged about how I mine and monitor alert.log here.
What to alert on? Anything where level < 16 also keep an eye on if comp_id=’VOS’.
System wait events
In case of using FSFO, your standby database is most likely in SYNC or FASTSYNC mode, this is having an impact on end user commit times. So good to keep an eye on commit timings.
V$SYSTEM_EVENT is a good view for this, but you have to sample it regularly and report on the deltas.
-- Need to sample this regularly. Report on deltas.
SELECT sys_extract_utc(systimestamp) sample_time, event
, time_waited_micro_fg
, time_waited_micro
FROM v$system_event
WHERE event in ('log file sync','log file parallel write','Redo Transport MISC','SYNC Remote Write');<RANT/>
Please only use UTC times (or TIMESTAMP WITH TIME ZONE) when developing your internal monitoring (or any other software). This is the global time standard for our planet. It is always growing, no strange jumps, everyone knows what it is. Local times belong only to the user interface layer.
Did I miss anything?
Most likely – but please tell me! I’m very interested in getting Data Guard FSFO monitoring rock solid.
Oracle REST Data Services
Recently ORDS also added a REST interface to query Data Guard properties. I have not yet checked it out, but potential for monitoring is high – especially to get around using the undocumented features.
At minimum need to trace what queries it is executing in the background to replicate them for custom monitoring 🙂
- Written by: ilmarkerm
- Category: Blog entry
- Published: March 6, 2023
It is possible to use DBMS_SQL to execute dynamic SQL in multiple pluggable databases, from CDB. Oracle does provide CONTAINERS clause, but the use of it is quite limited.
In this example I execute from CDB and I’m stopping all services in all PDB-s, transactionally.
- Written by: ilmarkerm
- Category: Blog entry
- Published: February 24, 2023
All posts in this series
- Part 1: Setup
- Part 2: Switchover
- Part 3: Failover
Switchover
Planned maintenance, need to take primary server down for maintenance. The obvious Data Guard command for role change in this case is SWITCHOVER, that changes database roles in a nice coordinated way and no standby requires reinstatement (flashback) after the operation.
Lets test it from the client perspective.
Scenario: Only local SYNC standby – no ADG
First I disable and remove failtesti3 instance (remote standby) from data guard configuration, so I only have two local database instances in the configuration, in SYNC mode. Physical standby is in MOUNT mode.
DGMGRL> show configuration verbose;
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti1 - Primary database
failtesti2 - (*) Physical standby database
(*) Fast-Start Failover target
Properties:
FastStartFailoverThreshold = '25'
OperationTimeout = '30'
TraceLevel = 'USER'
FastStartFailoverLagLimit = '30'
CommunicationTimeout = '180'
ObserverReconnect = '1800'
FastStartFailoverAutoReinstate = 'TRUE'
FastStartFailoverPmyShutdown = 'TRUE'
BystandersFollowRoleChange = 'ALL'
ObserverOverride = 'FALSE'
ExternalDestination1 = ''
ExternalDestination2 = ''
PrimaryLostWriteAction = 'FAILOVER'
ConfigurationWideServiceName = 'QKNPUXMZ_CFG'
Fast-Start Failover: Enabled in Zero Data Loss Mode
Lag Limit: 30 seconds (not in use)
Threshold: 25 seconds
Active Target: failtesti2
Potential Targets: "failtesti2"
failtesti2 valid
Observer: failtest-observer
Shutdown Primary: TRUE
Auto-reinstate: TRUE
Observer Reconnect: 1800 seconds
Observer Override: FALSE
Configuration Status:
SUCCESS
To execute DGMGRL commands I log remotely in using username and password.
dgmgrl "c##dataguard/sysdgpassword@connstr" "show configuration"
Start swingbench and start the testing program.
$ charbench ...
$ python failtest.py switchover_local_only_mountAll working well, now execute switchover
date -Iseconds ; dgmgrl "c##dataguard/sysdgpassword@connstr" "switchover to failtesti2" ; date -Iseconds
2023-02-14T10:23:27+00:00
DGMGRL for Linux: Release 19.0.0.0.0 - Production on Tue Feb 7 09:29:43 2023
Version 19.16.2.0.0
Connected to "failtesti1"
Connected as SYSDG.
Performing switchover NOW, please wait...
Operation requires a connection to database "failtesti2"
Connecting ...
Connected to "failtesti2"
Connected as SYSDG.
New primary database "failtesti2" is opening...
Operation requires start up of instance "failtesti1" on database "failtesti1"
Starting instance "failtesti1"...
Please complete the following steps to finish switchover:
start up and mount instance "failtesti1" of database "failtesti1"
2023-02-14T10:24:44+00:00Alert.log from new primary failtesti2 (cleaned)
2023-02-14T10:23:35.264043+00:00 ALTER DATABASE SWITCHOVER TO PRIMARY (failtesti2) 2023-02-14T10:23:36.544532+00:00 Background Media Recovery process shutdown (failtesti2) 2023-02-14T10:23:39.430461+00:00 rmi (PID:3337550): Database role cleared from PHYSICAL STANDBY [kcvs.c:1114] Switchover: Complete - Database mounted as primary 2023-02-14T10:23:41.542728+00:00 ALTER DATABASE OPEN 2023-02-14T10:23:46.293995+00:00 Completed: ALTER DATABASE OPEN ALTER PLUGGABLE DATABASE ALL OPEN 2023-02-14T10:23:48.984619+00:00 SOEFAIL(3):Started service soe/soe/soe.prod1.dbs 2023-02-14T10:23:48.985369+00:00 Pluggable database SOEFAIL opened read write Completed: ALTER PLUGGABLE DATABASE ALL OPEN
Alert.log from old primary failtesti1
2023-02-14T10:23:31.344766+00:00 ALTER DATABASE SWITCHOVER TO 'failtesti2' 2023-02-14T10:23:32.055470+00:00 ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY [Process Id: 2418351] (failtesti1) 2023-02-14T10:23:33.067341+00:00 Primary will check for some target standby to have received all redo RSM0 (PID:2418351): Waiting for target standby to apply all redo 2023-02-14T10:23:39.432887+00:00 RSM0 (PID:2418351): Switchover complete. Database shutdown required TMI: dbsdrv switchover to target END 2023-02-14 10:23:39.432896 Completed: ALTER DATABASE SWITCHOVER TO 'failtesti2'
Looking at the alert.log I see that 2023-02-14T10:23:31.344766+00:00 old primary database initiated the switchover procedure and 2023-02-14T10:23:48.985369+00:00 the new primary database was ready to accept connections. Taking 17.64s.
Lets see what client saw at the same time.
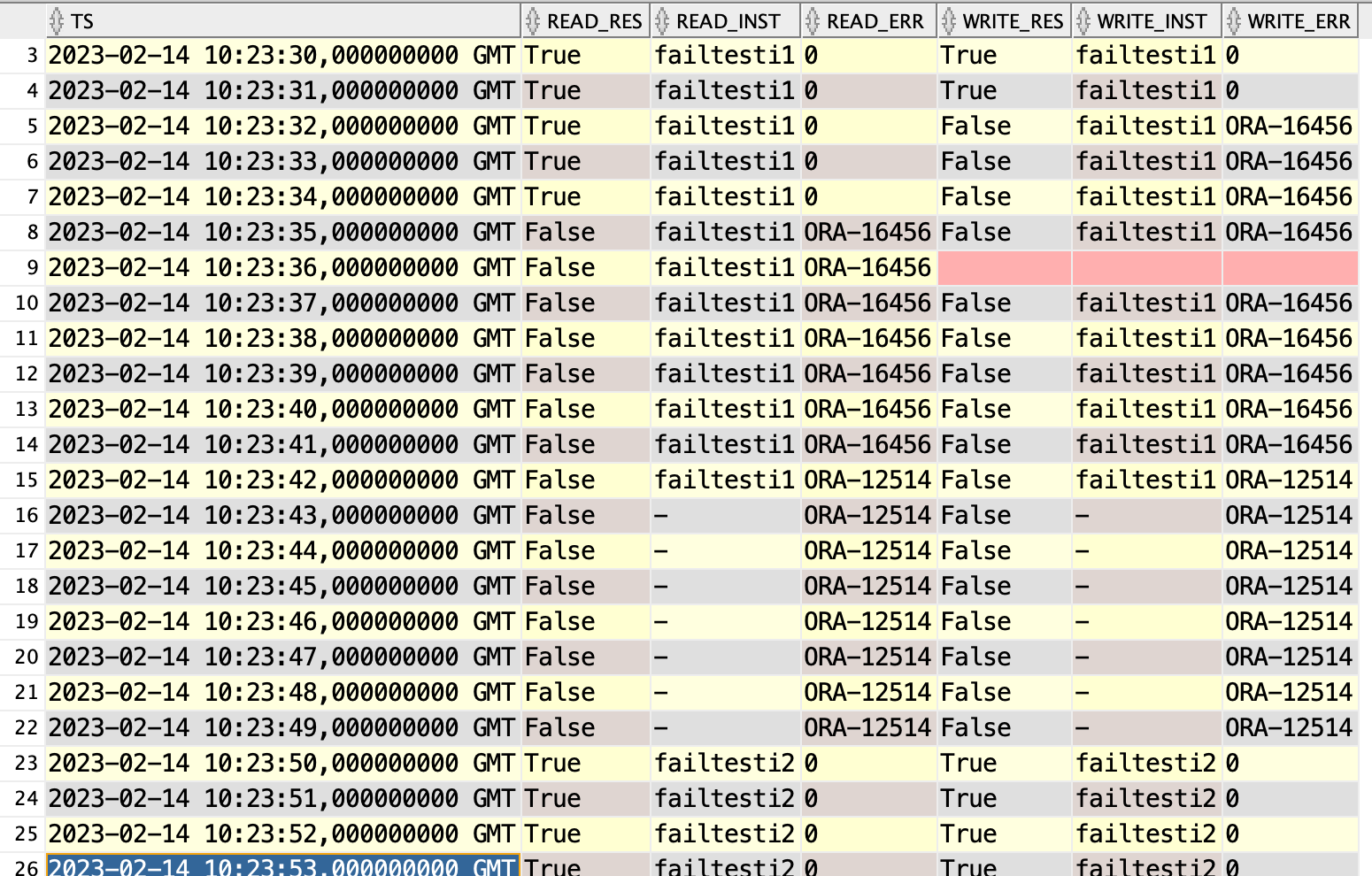
What I can see from it is that reads are allowed for a few seconds after switchover was initiated, making total downtime 14 seconds. Writes are closed immediately, so downtime for the client 17s. I actually expeted reads to be allowed for 4 more seconds, right until 2023-02-14T10:23:39 when alert.log reports Switchover complete. Something is not right, must retest this.
Scenario: Only local SYNC standby – with ADG
Lets repeat the test, but now the target standby CDB is open in READ ONLY mode. But pluggable databases are in MOUNTED mode (to prevent the service starting). So Active Data Guard is activated (LICENSE WARNING!).
SQL>sho pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 SOEFAIL MOUNTED
Data Guard status
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti2 - Primary database
failtesti1 - (*) Physical standby database
Fast-Start Failover: Enabled in Zero Data Loss Mode
Configuration Status:
SUCCESS (status updated 29 seconds ago)
Executing “switchover to failtesti1”
date -Iseconds ; dgmgrl "c##dataguard/sysdgpassword@connstr" "switchover to failtesti1" ; date -Iseconds 2023-02-14T10:39:13+00:00 Connected to "failtesti1" Connected as SYSDG. Performing switchover NOW, please wait... New primary database "failtesti1" is opening... Operation requires start up of instance "failtesti2" on database "failtesti2" Starting instance "failtesti2"...
Alert.log from new primary failtesti1
2023-02-14T10:39:19.896716+00:00 ALTER DATABASE SWITCHOVER TO PRIMARY (failtesti1) 2023-02-14T10:39:21.177020+00:00 Background Media Recovery process shutdown (failtesti1) 2023-02-14T10:39:27.007310+00:00 Completed: alter pluggable database all close immediate 2023-02-14T10:39:32.184760+00:00 CLOSE: all sessions shutdown successfully. Completed: alter pluggable database all close immediate 2023-02-14T10:39:33.404812+00:00 Switchover: Complete - Database mounted as primary TMI: kcv_commit_to_so_to_primary Switchover from physical END 2023-02-14 10:39:33.532617 SWITCHOVER: completed request from primary database. 2023-02-14T10:39:37.033131+00:00 ALTER DATABASE OPEN 2023-02-14T10:39:43.467549+00:00 SOEFAIL(3):Started service soe/soe/soe.prod1.dbs 2023-02-14T10:39:43.468294+00:00 Pluggable database SOEFAIL opened read write 2023-02-14T10:39:43.694199+00:00 Completed: ALTER DATABASE OPEN ALTER PLUGGABLE DATABASE ALL OPEN Completed: ALTER PLUGGABLE DATABASE ALL OPEN
Alert.log from old primary failtesti2
2023-02-14T10:39:16.016238+00:00 ALTER DATABASE SWITCHOVER TO 'failtesti1' 2023-02-14T10:39:16.711884+00:00 ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY [Process Id: 2441633] (failtesti2) 2023-02-14T10:39:17.723971+00:00 RSM0 (PID:2441633): Waiting for target standby to apply all redo 2023-02-14T10:39:19.547345+00:00 Switchover: Complete - Database shutdown required TMI: kcv_switchover_to_target convert to physical END 2023-02-14 10:39:19.567773 RSM0 (PID:2441633): Sending request(convert to primary database) to switchover target failtesti1 2023-02-14T10:39:33.534253+00:00 RSM0 (PID:2441633): Switchover complete. Database shutdown required
According to alert.log switchover took from 2023-02-14T10:39:16.016238+00:00 to 2023-02-14T10:39:43.467549+00:00 (when service opened), so 27.45s… surprise, did not expect this.
And now the client perspective.
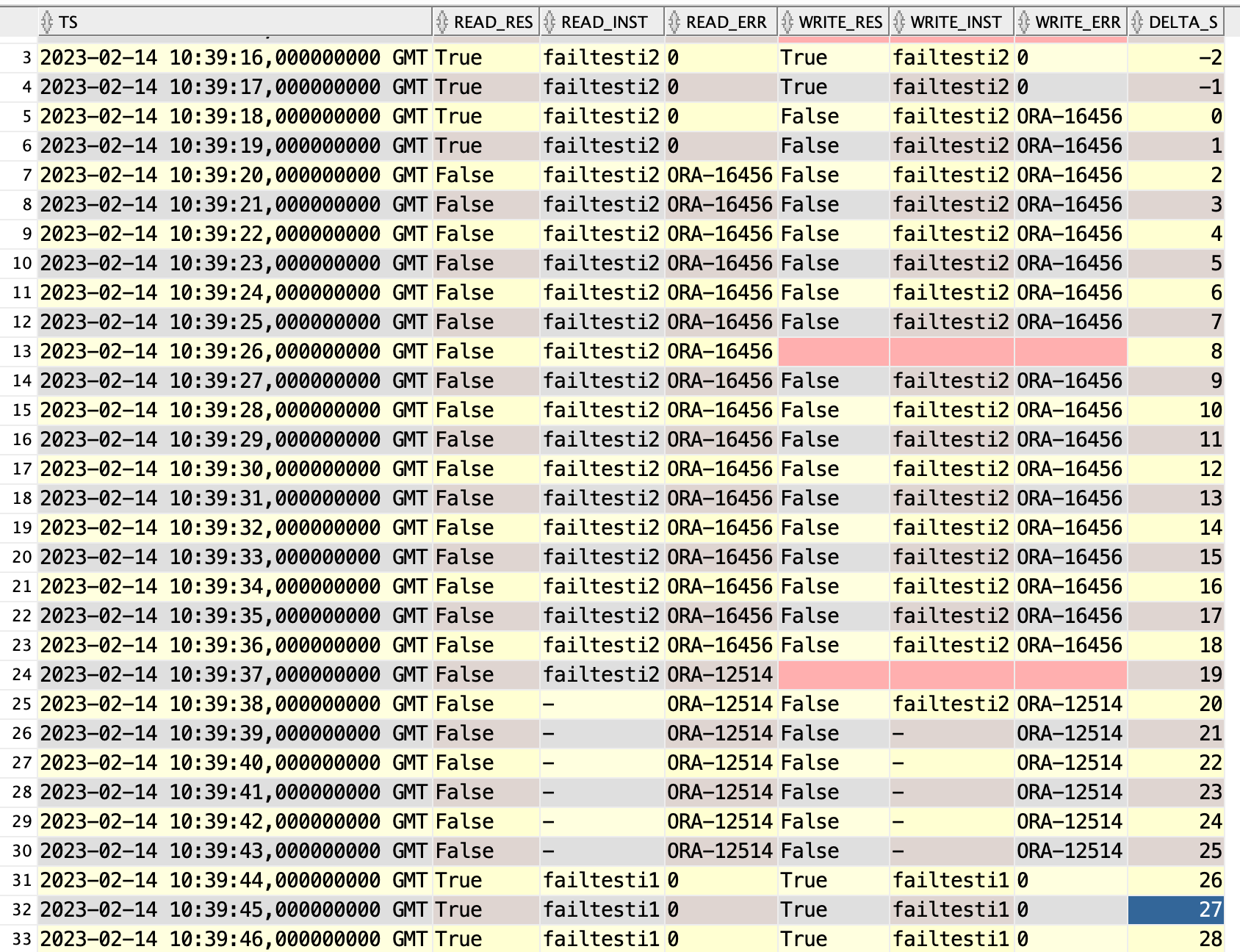
Same story as before, but having the target database open (Active Data Guard) adds about 9-10s to the downtime. From alert.log it looks like it needs to close all read only pluggable databases before switchover completes.
Scenario: Local SYNC standby and remote ASYNC standby – no ADG
Now in addition to local SYNC standby, I’ll add a remote ASYNC standby failtesti3 in the configuration, which is 53ms away (ping time). But I’m still ony interested in the role change between failtesti1 and failtesti2.
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti1 - Primary database
failtesti2 - (*) Physical standby database
failtesti3 - Physical standby database
Fast-Start Failover: Enabled in Zero Data Loss Mode
Configuration Status:
SUCCESS (status updated 31 seconds ago)
Start the tests and do switchover.
date -Iseconds ; dgmgrl "c##dataguard/sysdgpassword@connstr" "switchover to failtesti2" ; date -Iseconds 2023-02-24T10:18:13+00:00 Connected to "failtesti1" Connected as SYSDG. Performing switchover NOW, please wait... Operation requires a connection to database "failtesti2" Connecting ... Connected to "failtesti2" Connected as SYSDG. New primary database "failtesti2" is opening... Operation requires start up of instance "failtesti1" on database "failtesti1" Starting instance "failtesti1"... 2023-02-24T10:19:35+00:00
From client perspective
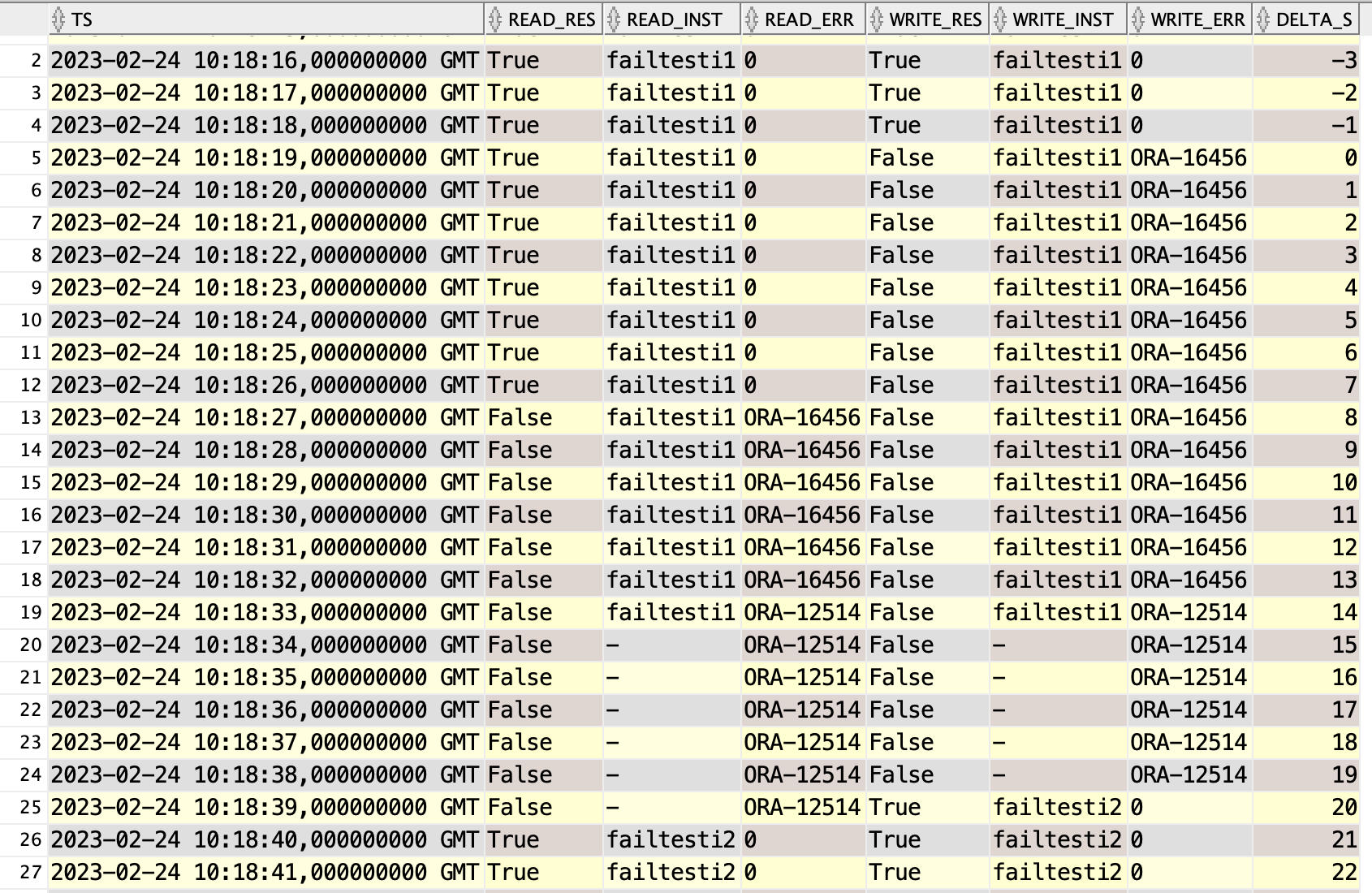
The remote standby made little difference. It added a few seconds to the switchover time, during which the old primary was still readable. During switchover Data Guard Broker must sync the configuration to all standbys.
Alert log from old primary failtest1
2023-02-24T10:18:18.128228+00:00 ALTER DATABASE SWITCHOVER TO 'failtesti2' 2023-02-24T10:18:18.827865+00:00 ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY [Process Id: 3284632] (failtesti1) ... 2023-02-24T10:18:25.855408+00:00 Switchover: Complete - Database shutdown required 2023-02-24T10:18:30.367681+00:00 RSM0 (PID:3284632): Switchover complete. Database shutdown required Completed: ALTER DATABASE SWITCHOVER TO 'failtesti2'
I see that reads on the old primary were allowed right until switchover was complete. Writes and disabled immediately. This is the behaviour I expect.
Scenario: Local SYNC standby and remote standby with lagging apply
Here my goal is to see what happens when the remote standby is lagging behind. Will it affect the local switchover? To simulate that I’ll stop apply on failtesti3 and let swingbench run for a longer time before initiating switchover.
DGMGRL> edit database failtesti3 set state='apply-off';
-- run swingbenh for a few hours
DGMGRL> edit database failtesti3 set state='apply-on';
-- immediately run switchoverBefore the test lets check how big the lag is on the remote standby. Before switchover I have over 3h lag, with over 40GB logs to apply on failtesti3.
DGMGRL> show configuration;
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti2 - Primary database
failtesti1 - (*) Physical standby database
failtesti3 - Physical standby database
Fast-Start Failover: Enabled in Zero Data Loss Mode
Configuration Status:
SUCCESS (status updated 37 seconds ago)
DGMGRL> edit database failtesti3 set state='apply-on';
Succeeded.
DGMGRL> show database failtesti3;
Database - failtesti3
Role: PHYSICAL STANDBY
Intended State: APPLY-ON
Transport Lag: 0 seconds (computed 0 seconds ago)
Apply Lag: 3 hours 7 minutes 36 seconds (computed 0 seconds ago)
Average Apply Rate: 88.35 MByte/s
Real Time Query: ON
Instance(s):
failtesti3
Database Warning(s):
ORA-16853: apply lag has exceeded specified threshold
Database Status:
WARNING
-- switchover
2023-02-24T13:37:45+00:00
Connected to "failtesti2"
Connected as SYSDG.
Performing switchover NOW, please wait...
Operation requires a connection to database "failtesti1"
Connecting ...
Connected to "failtesti1"
Connected as SYSDG.
New primary database "failtesti1" is opening...
Operation requires start up of instance "failtesti2" on database "failtesti2"
Starting instance "failtesti2"...
2023-02-24T13:39:06+00:00
DGMGRL> show database failtesti3;
Database - failtesti3
Role: PHYSICAL STANDBY
Intended State: APPLY-ON
Transport Lag: 0 seconds (computed 0 seconds ago)
Apply Lag: 2 hours 28 minutes 47 seconds (computed 0 seconds ago)
Average Apply Rate: 110.65 MByte/s
Real Time Query: ON
Instance(s):
failtesti3
After the switchover I still have plenty of lag in failtesti3 to apply.
What did the client see?
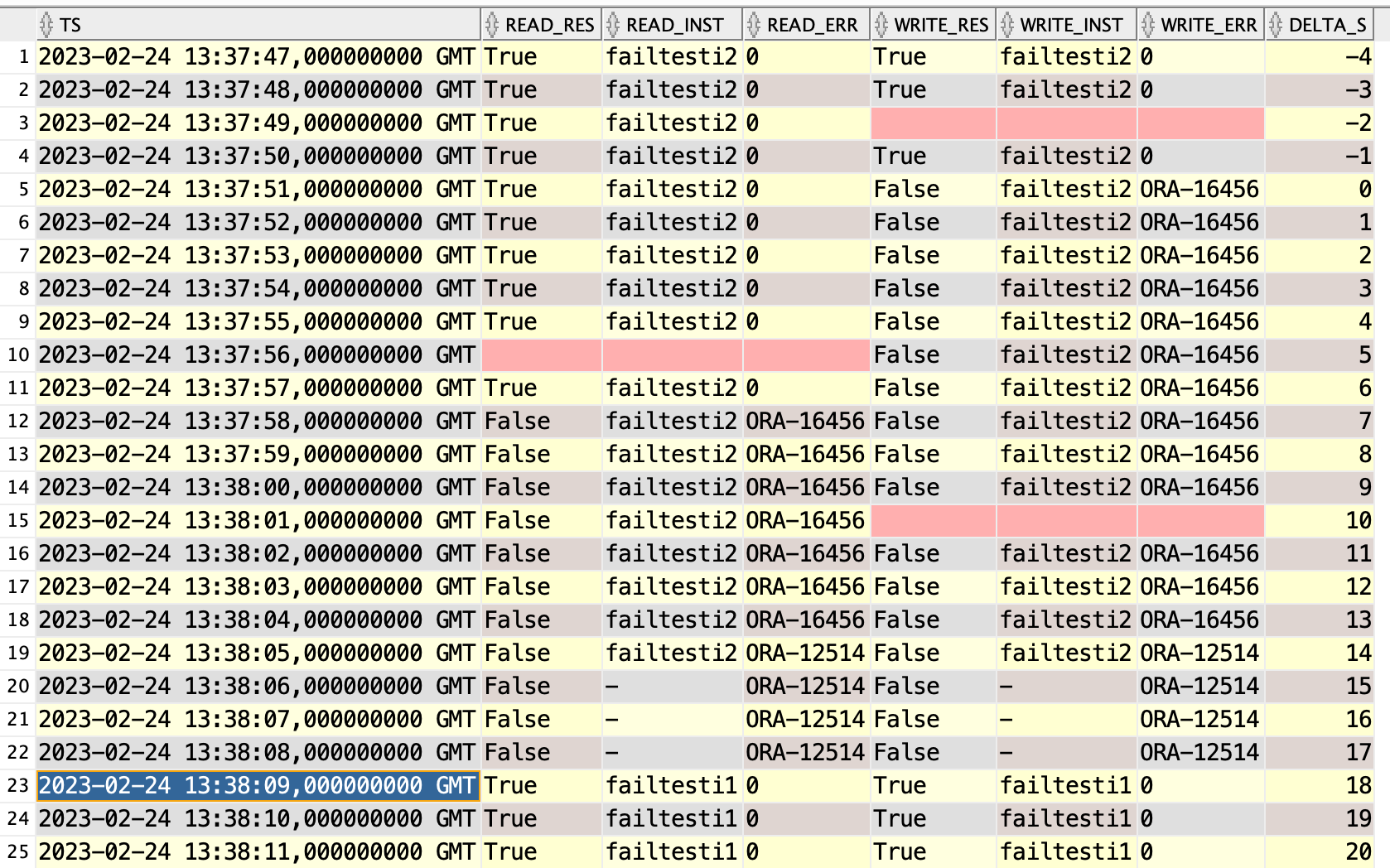
I don’t see any real difference to the test without the lag.
Scenario: Local SYNC standby and remote standby with lagging transport
Lets try again, but now I’ll change transport to remote failtesti3 standby to ARCH mode, expecting that during switchover it would need to transport a few GB.
DGMGRL> edit database failtesti3 set property logxptmode='arch';
-- run swingbench, so it has quite a few GB of redo collected before logswitch
2023-02-24T14:14:43+00:00
DGMGRL> switchover to failtesti2;
Connected to "failtesti1"
Connected as SYSDG.
Performing switchover NOW, please wait...
Operation requires a connection to database "failtesti2"
Connecting ...
Connected to "failtesti2"
Connected as SYSDG.
New primary database "failtesti2" is opening...
Operation requires start up of instance "failtesti1" on database "failtesti1"
Starting instance "failtesti1"...
2023-02-24T14:19:49+00:00Finally… significantly slower switchover, taking minutes. How did the client see it?
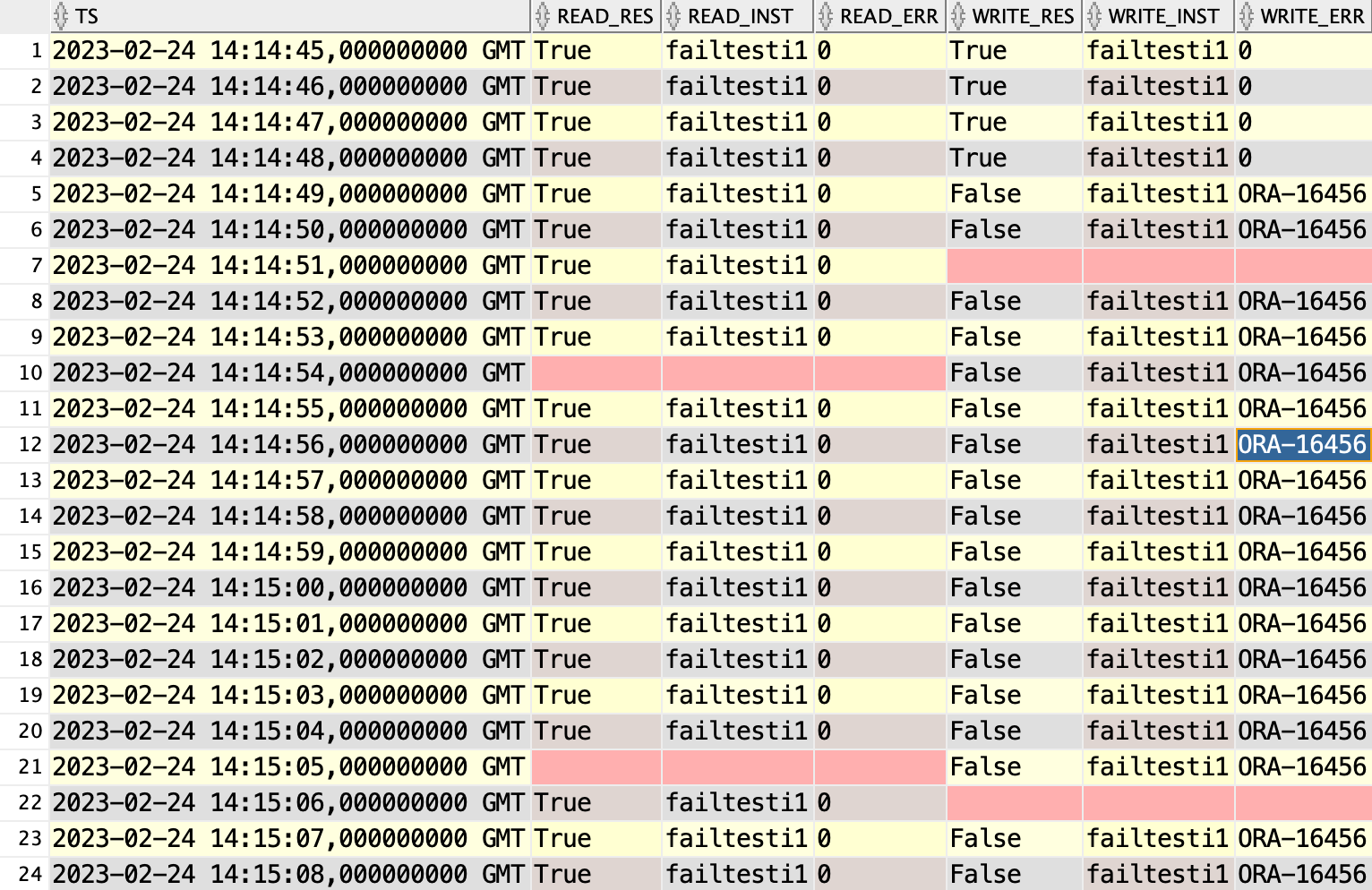
And it continues this way for minutes… until
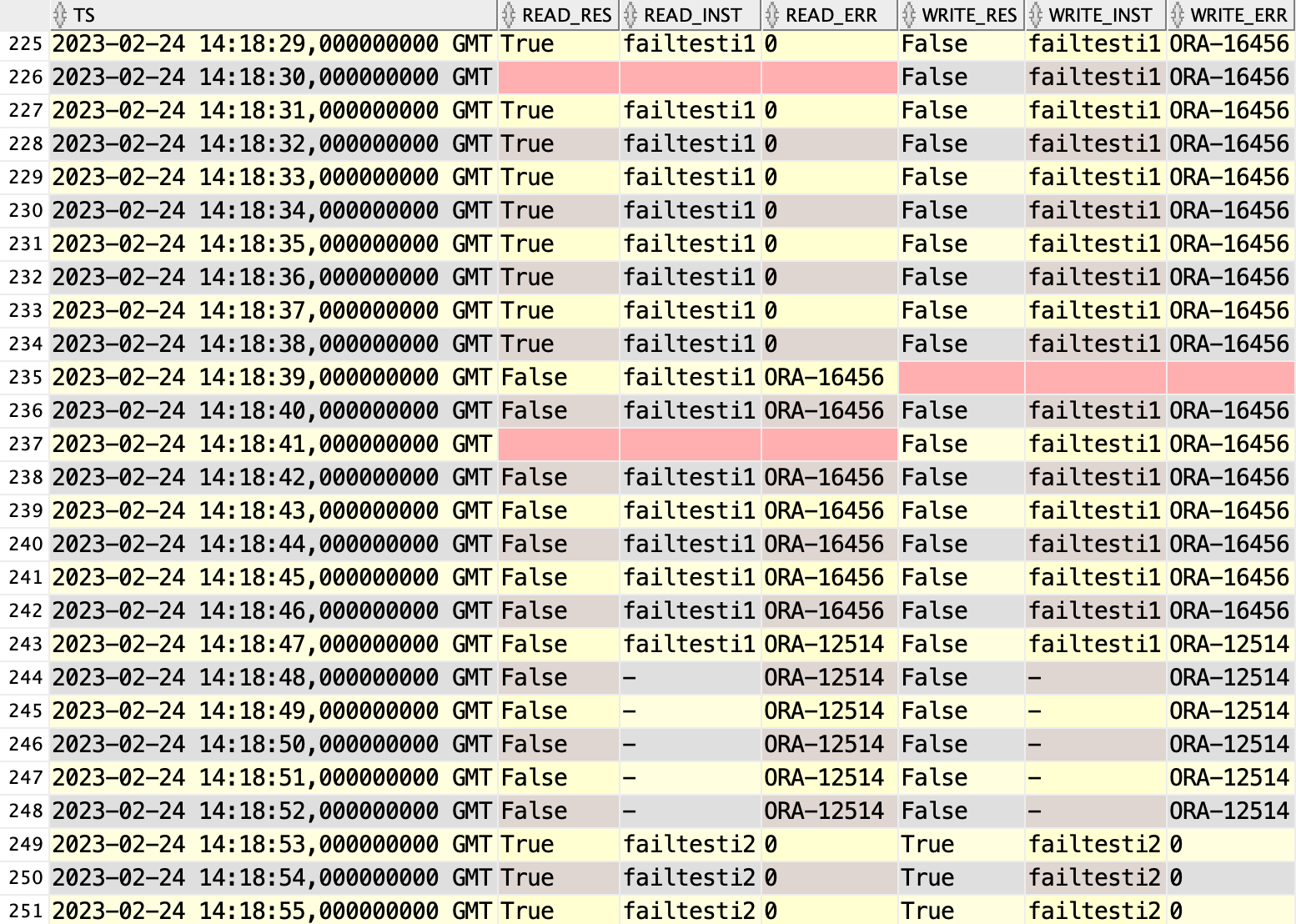
Read queries were still only down for about 13s, but writes were down for 4min 3s! That is the time it took to send the archived logfile to the remote standby. In my test the logfile was 3GB is size.
Lets look at the old primary alert.log
2023-02-24T14:14:48.009629+00:00 ALTER DATABASE SWITCHOVER TO 'failtesti2' 2023-02-24T14:14:48.714313+00:00 ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY [Process Id: 2332229] (failtesti1) 2023-02-24T14:14:49.727293+00:00 RSM0 (PID:2332229): Generating and shipping final logs to target standby Switchover End-Of-Redo Log thread 1 sequence 858 has been fixed Switchover: Primary highest seen SCN set to 0x0000000017d7d99f RSM0 (PID:2332229): Noswitch archival of T-1.S-858 RSM0 (PID:2332229): End-Of-Redo Branch archival of T-1.S-858 RSM0 (PID:2332229): LGWR is actively archiving to LAD:2 2023-02-24T14:18:38.393413+00:00 RSM0 (PID:2332229): Archiving is disabled due to current logfile archival Primary will check for some target standby to have received all redo RSM0 (PID:2332229): Waiting for target standby to apply all redo 2023-02-24T14:18:43.333433+00:00 RSM0 (PID:2332229): Switchover complete. Database shutdown required
I don’t really see any log entry that specifically says that it is waiting for the remote standby to receive the latest redo, although this is what it must be waiting on.
Anyway, good thing to know in case of performing switchovers. Make sure ALL standbys in configuration have minimal amount of redo to ship during switchover.
RETEST! Only local SYNC standby – no ADG
Don’t really understand why in my first test without any remote long distance standby, reads were stopped too early. I expected the old standby to be readable up until the very last moment of the switchover. Lets try again.
DGMGRL> remove database failtesti3;
Removed database "failtesti3" from the configuration
DGMGRL> show configuration;
Configuration - failtest
Protection Mode: MaxAvailability
Members:
failtesti2 - Primary database
failtesti1 - (*) Physical standby database
Fast-Start Failover: Enabled in Zero Data Loss Mode
Configuration Status:
SUCCESS (status updated 11 seconds ago)
2023-02-24T14:53:48+00:00
DGMGRL> switchover to failtest1;
Connected to "failtesti2"
Connected as SYSDG.
Performing switchover NOW, please wait...
Operation requires a connection to database "failtesti1"
Connecting ...
Connected to "failtesti1"
Connected as SYSDG.
New primary database "failtesti1" is opening...
Operation requires start up of instance "failtesti2" on database "failtesti2"
Starting instance "failtesti2"...
2023-02-24T14:55:06+00:00
What did the client see?

A little bit faster this time. 12s downtime for reads, 15s downtime for writes.
Take-aways
- During switchover reads are permitted as long as possible, writes are blocked immediately when switchover starts with ORA-16456.
- Having Active Data Guard database as the switchover target adds about 10s to the switchover time.
- Having far away ASYNC standby databases will add a few seconds to the switchover time. Minimal.
- But if one of the BYSTANDER remote standby databases is having a transport lag, during switchover writes will be blocked for quite a long time, depending on how long it will take to transport the missing redo. Apply lag did not have the same effect.
Next…
Failover methods