Tag: apex
- Written by: ilmarkerm
- Category: Blog entry
- Published: October 28, 2023
JSON Web Token (JWT) is a popular open standard that enables web applications to transfer information between parties asn JSON object. For example single-sign on authentication information. The information can be trusted, because the token also includes a signature. Verifying this signature is essential, otherwise anyone can fake the token contents.
Oracle APEX does provide APEX_JWT package, which handles the parsing and validity checking very well, but it can only verify the signature, if JWT was created using HS256 signature. HS256 is loosing popularity, since it is based on symmetric cryptography, meaning all parties must have access to the same encryption key.
Another, much more secure signature is now gaining popularity, based on RSA public key encryption – RS256. Here JWT is signed using a private key, but it can be verified using the corresponding public key. As the name suggests, public key is completely public and can be downloaded from the internet using kid attribute value present in JWT header (this service is called JWKS – JSON Web Key Sets). This is also the signature system AWS Cognito uses.
At the time of writing (APEX 23.1 and Oracle database 19.20), I did not find and ready code on the internet for verifying JWT RS256 signatures – so I had to create one. It lets APEX_JWT do the JWT parsing and validity checking, but I needed to add RS256 signature checking and downloading keys from JWKS store. It is intended to be used from APEX flows.
APEX_JWT_RS256 package repository can be found here
A quick example how to use the package as APEX page sentry function in custom authentication scheme.
create or replace FUNCTION JWT_PAGE_SENTRY RETURN BOOLEAN AS
v_required_group varchar2(30):= 'important_people'; -- Group needed to access the app
v_iss varchar2(200):= 'https://cognito-idp.eu-central-1.amazonaws.com/eu-central-1_ZZxxZZxx11'; -- ISS that issued the JWT, YOU MUST CHANGE THIS to point to your own ISS
jwt_cookie owa_cookie.cookie;
v_jwt_payload varchar2(2000);
v_jwt_json json_object_t;
v_groups json_array_t;
v_group_found boolean:= false;
BEGIN
-- Do JWT token validation and check that correct group is granted to user
-- 2023 Ilmar Kerm
jwt_cookie:= owa_cookie.get('JWT_COOKIE_NAME');
IF jwt_cookie.vals.COUNT = 0 THEN
apex_debug.error('JWT session cookie not found');
RETURN false;
END IF;
IF apex_jwt_rs256.decode_and_validate(jwt_cookie.vals(1), v_iss, v_jwt_payload) THEN
-- JWT validated, now check the required group
v_jwt_json:= json_object_t.parse(v_jwt_payload);
v_groups:= v_jwt_json.get_array('cognito:groups');
FOR i IN 0..v_groups.get_size - 1 LOOP
IF v_groups.get_string(i) = v_required_group THEN
v_group_found:= true;
EXIT;
END IF;
END LOOP;
IF NOT v_group_found THEN
apex_debug.error('Required group is missing from JWT: '||v_required_group);
RETURN false;
END IF;
IF v_jwt_json.get_string('token_use') != 'access' THEN
apex_debug.error('Invalid value for JWT attribute token_use');
RETURN false;
END IF;
IF V('APP_USER') IS NULL OR V('APP_USER') = 'nobody' OR V('APP_USER') != v_jwt_json.get_string('username') THEN
APEX_CUSTOM_AUTH.DEFINE_USER_SESSION(
p_user => v_jwt_json.get_string('username'),
p_session_id => APEX_CUSTOM_AUTH.GET_NEXT_SESSION_ID
);
END IF;
RETURN true;
ELSE
RETURN false;
END IF;
END JWT_PAGE_SENTRY;- Written by: ilmarkerm
- Category: Blog entry
- Published: August 5, 2023
Tim has written an excellent blog post on how to connect your APEX application with Azure SSO. I used this article as a base with my work, with a few modifications.
You can also set Authentication provider to OpenID Connect Provider, then you only have to supply one Azure SSO configuration URL, everything else will be automatically configured. Documentation is here. You can configure like that:
- Authentication provider: OpenID Connect Provider
- Discovery URL: https://login.microsoftonline.com/your_Azure_AD_tenant_UUID_here/v2.0/.well-known/openid-configuration
For Oracle Wallet setup, you can use my solution to automatically convert Linux system trusted certificates to Oracle Wallet format.
Another requirement for me was to make some Azure user group membership available for the APEX application. One option to query this from APEX is to make a post authentication call to Azure GraphQL endpoint /me/memberOf. For this to work, Azure administrator needs to grant your application User.Read privilege at minimum. Then /me/memberOf will list you only the group object ID-s that the logged in user is a member, but no group names nor other information (if you require to see group names, then your application also needs Group.Read.All permission, but for my case it required approvals and more red tape that I really did not want to go through).
The solution below is to create APEX post authentication procedure that will store the Azure enabled roles in APEX user session collection APP_USER_ENABLED_ROLES. Afterwards you can use the collection in APEX application as you see fit, also use it in APEX authorization schemes.
- Written by: ilmarkerm
- Category: Blog entry
- Published: July 20, 2023
In order to prepare for APEX 23.1 upgrade in production, I upgraded several test environments from existing 21.1.5 to 23.1.3. Nothing special about the upgrade, no errors. But then developers requested I downgrade one of the environments back to 21.1, since they needed to make some changes to existing apps.
APEX downgrade should be easy, since APEX always installs new version into a new schema (23.1 goes to APEX_230100, 21.1 is installed in APEX_210100) and then it just copies over the application metadata. Downgrade then it should be easy, just point APEX back to the old schema. Downgrade is documented and Oracle does provide apxdwngrd.sql script for it.
After running apxdwngrd.sql and dropping APEX_230100 schema – the users started receiving a page from ORDS that “Application Express is currently unavailable”.
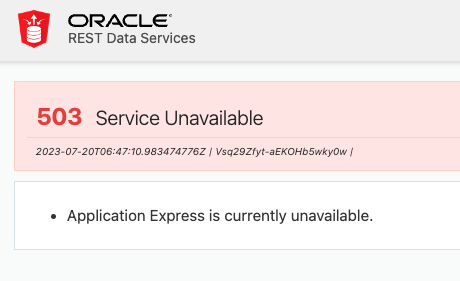

No other information, no other error message in ORDS logs, no errors in alert.log. How does it determine that APEX is unavailable? No idea.
I did the usual checks, I saw ORDS sessions connected to the database, so there were no connection issues.
SQL> select * from dba_registry where comp_id='APEX';
version = 21.1.5
status = VALID
procedure = VALIDATE_APEX
SQL> exec sys.validate_apex;
PL/SQL procedure successfully completed.
SQL> select * from dba_registry where comp_id='APEX';
version = 21.1.5
status = VALID
APEX component in the database is valid, with correct version and after validation it is still VALID.
SQL> select count(*) from dba_objects where owner='APEX_210100' and status != 'VALID';
0There are no invalid objects in the APEX schema, but I did see some public synonyms still left over from APEX 23.1. And then recreated all APEX 21.1 public synonyms.
SQL> select 'drop public synonym '||synonym_name||';' from dba_synonyms where owner='PUBLIC' and table_owner like 'APEX_230100';
... cleaned them up
SQL> alter session set current_schema = APEX_210100;
SQL> exec wwv_flow_upgrade.recreate_public_synonyms('APEX_210100');No help… Still the same “Application Express is currently unavailable” to the users.
After that I got a useful tip in twitter to check view APEX_RELEASE.

Version is correct, but PATCH_APPLIED=APPLYING? That cannot be right and checking the not yet upgraded source production database it said PATCH_APPLIED=APPLIED.
First I tried to reapply 21.1.5 patch, and then 21.1.7 patch, but none of them reset this PATCH_APPLIED field.
Time to dig into APEX internals. I see that PATCH_APPLIED field is populated using function call wwv_flow_platform.get_patch_status_and_init_cgi but the code for it is wrapped. We also have the good old SQL trace that showed me that this fuction is calling
SELECT VALUE FROM APEX_210100.WWV_FLOW_PLATFORM_PREFS WHERE NAME = 'APEX_PATCH_STATUS';And there is see value APPLYING as a plain string. What if I just update it?
update APEX_210100.WWV_FLOW_PLATFORM_PREFS set value='APPLIED' WHERE NAME = 'APEX_PATCH_STATUS';And the “Application Express is currently unavailable” message is gone and APEX works again! My guess is that something in the 23.1 upgrade process sets the old schema to APPLYING mode and then downgrade does not reset it. Sounds like a bug.
NB! Don’t do it in production – talk to Oracle Support first. I only did it because it was development environment and developers wanted to get their environment back fast.
- Written by: ilmarkerm
- Category: Blog entry
- Published: October 20, 2010
There is an interesting W3C Draft, that enables websites to just simply ask web browser to report the users geographical location, and then the web browser will try the best available location method, like GeoIP, WIFI location or GPS. I have currently tested it on Firefox 3.6 and Google Chrome; Internet Explorer 8.0 does not support it yet.
W3C Geolocation API Draft
Mozilla documentation for Geolocation
How to use it in APEX?
If you are just interested in recording the users location, then using an on-demand application process should be the easiest solution:
First, create two application items: USER_LOC_LATITUDE and USER_LOC_LONGITUDE. They are used for storing users location.
Then, create an On Demand application process SAVE_USER_LOCATION. Create your necessary application logic in that process to handle the user location. The user location is available through application items USER_LOC_LATITUDE and USER_LOC_LONGITUDE.
And finally, include the following HTML code to your page. This uses APEX AJAX JavaScript API to call the created application process as soon as the users location becomes available for the browser. Please note also, that the browser asks for users permission for reporting the location.
<script type="text/javascript">
if(navigator.geolocation) {
navigator.geolocation.getCurrentPosition(function(position) {
var get = new htmldb_Get(null, $x('pFlowId').value,
'APPLICATION_PROCESS=SAVE_USER_LOCATION', 0);
get.add('USER_LOC_LATITUDE', position.coords.latitude);
get.add('USER_LOC_LONGITUDE', position.coords.longitude);
gReturn = get.get();
get = null;
});
}
</script>
To continuously monitor user position, use the function navigator.geolocation.watchPosition instead of navigator.geolocation.getCurrentPosition.
Resolving coordinates to location name
Here is one package, that uses GeoNames.org database for resolving the location name. The package requires Oracle 11.2.
The geolocation package
One helper package, HTTP_UTIL, for downloading XML over HTTP
- Written by: ilmarkerm
- Category: Blog entry
- Published: July 22, 2009
I have attended some APEX presentations/seminars and one question seems to be repeating and got my attention. Can APEX run on another database?
Well, APEX itself or APEX application itself cannot run in any way on another database besides Oracle. APEX is PL/SQL application and no other database supports Oracle PL/SQL language.
But it’s possible to select and modify data from another database from your APEX application.
First of all you need to set up a database link to the other database using Oracle Heterogeneous Services/Transparent Gateways. I’m not going to get into that right now, please use documentation/google for that.
I’m going to name my database link HSDB:
create database link hsdb connect to "lowercaseusername" identified by "randomCasepaSSword" using 'MYSQL_DB_SERVICE';
I’m going to use MySQL database and I’ll create table employees on MySQL database:
CREATE TABLE `employees` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `first_name` varchar(100) NOT NULL, `last_name` varchar(100) NOT NULL, `personal_code` varchar(20) NOT NULL, `birthday` date DEFAULT NULL, `salary` decimal(10,2) NOT NULL, `is_active` tinyint(4) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Test that table employees is accessible from Oracle:
select * from "employees"@hsdb;
NB! I created the table in MySQL with a lower case table name, but Oracle uses upper case identifiers by default, unless you force the correct case with double-quotes.
One other thing to look out for: check that ODBC/Oracle do not translate any of the columns to the deprecated LONG datatype. LONG columns seems to be used for long/unlimited text fields (text in MySQL, text in PostgreSQL). You can check it by running DESC command from SQLPLUS.
desc "employees"@hsdb Name Null? Type -------------------------- -------- ----------------- id NUMBER(10) first_name NOT NULL VARCHAR2(100) last_name NOT NULL VARCHAR2(100) personal_code NOT NULL VARCHAR2(20) birthday DATE salary NOT NULL NUMBER(10,2) is_active NOT NULL NUMBER(3)
Make sure, that none of the data types is LONG. If you have LONG column, then you need to modify the data type from the source database or create a “Oracle friendly” view on top of it.
In PostgreSQL ODBC driver its also possible to modify the maximum VARCHAR length before its mapped to LONG.
Anyway, this is the most critical part in my opinion. Make sure that you are happy with the data type mappings before continuing!
Now create an Oracle view on top that MySQL table. This view will translate all column names to upper case and will simplify writing the SQL code.
CREATE VIEW EMPLOYEES_MYSQL AS
SELECT "id" id,
"first_name" first_name,
"last_name" last_name,
"personal_code" personal_code,
"birthday" birthday,
"salary" salary,
"is_active" is_active
FROM "employees"@hsdb;
desc employees_mysql
Name Null? Type
----------------------- -------- ----------------
ID NUMBER(10)
FIRST_NAME NOT NULL VARCHAR2(300)
LAST_NAME NOT NULL VARCHAR2(300)
PERSONAL_CODE NOT NULL VARCHAR2(60)
BIRTHDAY DATE
SALARY NOT NULL NUMBER(10,2)
IS_ACTIVE NOT NULL NUMBER(3)
Simple report
Creating a simple report is very easy, just use the created EMPLOYEES_MYSQL view in APEX like any other normal Oracle table/view.
Complex report
Writing vanilla-SQL against non-Oracle table over database link usually works, when the SQL is really simple. But there are pretty serious limitations and in some cases the performance “may not be very good” (indexes not used for some data type conversions).
To solve that problem, Oracle has a package DBMS_HS_PASSTHROUGH, that sends unmodified native SQL query to the linked database.
For this example I’ll use the following native MySQL SQL statement for a report:
select sql_cache id, first_name, last_name from employees limit 10
To be able to use this result in a SQL statement, I’m going to use PIPELINED function and for that I first need to create TYPE, that will define the structure of the query output. And after that I’ll create the actual function that will query the remote database.
create or replace type mysql_hstest_type as object (
id number,
first_name varchar2(250),
last_name varchar2(250)
);
/
create or replace type tab_mysql_hstest_type is
table of mysql_hstest_type;
/
create or replace FUNCTION mysql_hstest_query
RETURN tab_mysql_hstest_type PIPELINED
IS
p_row mysql_hstest_type:= mysql_hstest_type(null, null, null);
p_c binary_integer;
BEGIN
p_c:= DBMS_HS_PASSTHROUGH.OPEN_CURSOR@hsdb;
DBMS_HS_PASSTHROUGH.PARSE@hsdb(p_c,
'select sql_cache id, first_name, last_name from employees limit 10');
WHILE DBMS_HS_PASSTHROUGH.FETCH_ROW@hsdb(p_c) > 0 LOOP
DBMS_HS_PASSTHROUGH.GET_VALUE@hsdb(p_c, 1, p_row.id);
DBMS_HS_PASSTHROUGH.GET_VALUE@hsdb(p_c, 2, p_row.first_name);
DBMS_HS_PASSTHROUGH.GET_VALUE@hsdb(p_c, 3, p_row.last_name);
PIPE ROW(p_row);
END LOOP;
DBMS_HS_PASSTHROUGH.CLOSE_CURSOR@hsdb(p_c);
RETURN;
END;
/
Now, to use it in an APEX form just use the following SQL in report:
select * from table(mysql_hstest_query)
Form
First create a form on a view EMPLOYEES_MYSQL with the wizard like for any normal table. This will just create all the necessary page elements quickly.
Its necessary to write optimistic locking feature, because “Automatic Row Processing (DML)” process cannot be used and optimistic locking is a “silent” built in feature of that process. If for some weird reason you do not want the optimistic locking feature, then you can skip the checksum and validation steps.
For checksumming I’ll create hashing function (this one needs execute privileges on DBMS_CRYPTO):
CREATE OR REPLACE FUNCTION form_md5_checksum(
p1 varchar2 default null, p2 varchar2 default null,
p3 varchar2 default null, p4 varchar2 default null,
p5 varchar2 default null, p6 varchar2 default null,
p7 varchar2 default null, p8 varchar2 default null,
p9 varchar2 default null, p10 varchar2 default null)
RETURN varchar2 DETERMINISTIC IS
BEGIN
RETURN rawtohex(DBMS_crypto.hash(UTL_RAW.CAST_TO_RAW(
p1||'|'||p2||'|'||p3||'|'||p4||'|'||
p5||'|'||p6||'|'||p7||'|'||p8||'|'||
p9||'|'||p10), DBMS_CRYPTO.HASH_MD5));
END;
/
Now create a new hidden and protected item in the APEX page, I’ll call it P3_CHECKSUM.
Then create a PL/SQL anonymous block process:
Name: Calculate checksum Sequence: 20 (just after Automated Row Fetch) Process Point: On Load - After Header Process:
BEGIN
:p3_checksum:= form_md5_checksum(
:p3_ID, :p3_FIRST_NAME, :p3_LAST_NAME, :p3_PERSONAL_CODE,
:p3_BIRTHDAY, :p3_SALARY, :p3_IS_ACTIVE);
END;
Then I removed “Database Action” from the form buttons and changed the Button Name (the page submit REQUEST value):
Delete - DELETE Apply Changes - UPDATE Create - INSERT
The default “Automatic Row Processing (DML)” process cannot be used for saving the chages back to the database, because the ODBC database/driver lacks the support for SELECT FOR UPDATE. Because of it, delete the existing “Automatic Row Processing (DML)” process.
To save the changes, a new procedure is needed:
CREATE OR REPLACE PROCEDURE modify_employees_mysql(
p_action IN VARCHAR2, p_row IN employees_mysql%rowtype,
p_md5 varchar2)
IS
PRAGMA AUTONOMOUS_TRANSACTION;
p_new_md5 varchar2(50);
p_new_row employees_mysql%rowtype;
BEGIN
-- Calculate checksum
IF p_action IN ('UPDATE','DELETE') AND p_row.id IS NOT NULL THEN
-- Lock the row
UPDATE employees_mysql SET first_name = first_name
WHERE id = p_row.id;
-- Calculate new checksum
SELECT * INTO p_new_row FROM employees_mysql WHERE id = p_row.id;
p_new_md5:= form_md5_checksum(p_new_row.ID, p_new_row.FIRST_NAME,
p_new_row.LAST_NAME, p_new_row.PERSONAL_CODE,
p_new_row.BIRTHDAY, p_new_row.SALARY, p_new_row.IS_ACTIVE);
-- Check if the checksum has changed
IF NVL(p_new_md5, '-') <> NVL(p_md5, '-') THEN
ROLLBACK;
raise_application_error(-20000, 'Data has changed');
END IF;
--
END IF;
-- Do the data modifications
IF p_action = 'INSERT' THEN
INSERT INTO employees_mysql VALUES p_row;
ELSIF p_action = 'UPDATE' AND p_row.id IS NOT NULL THEN
UPDATE employees_mysql SET ROW = p_row WHERE id = p_row.id;
ELSIF p_action = 'DELETE' AND p_row.id IS NOT NULL THEN
DELETE FROM employees_mysql WHERE id = p_row.id;
ELSE
raise_application_error(-20099, 'Invalid action.');
END IF;
commit;
END;
/
Note the “PRAGMA AUTONOMOUS_TRANSACTION” in the above code. I used the default open source MySQL ODBC driver that lacks the support for 2PC (Two Phase Commit). The symptom for this “ORA-02047: cannot join the distributed transaction in progress” when running the procedure inside APEX transaction.
If you are using some commercial ODBC driver with 2PC support or drivers supplied by Oracle HS or Oracle Transparent Gateways, then you don’t need autonomous transaction for this procedure and you also need to remove commit/rollback statements from the procedure.
And finally put this procedure to the APEX page flow.
Create a new PL/SQL anonymous block process:
Name: Save changes Sequence: 30 Process Point: On Submit - After Computations and Validations Process:
DECLARE p_row employees_mysql%rowtype; BEGIN p_row.id:= :P3_ID; p_row.first_name:= :P3_FIRST_NAME; p_row.last_name:= :P3_LAST_NAME; p_row.personal_code:= :P3_PERSONAL_CODE; p_row.birthday:= :P3_BIRTHDAY; p_row.salary:= :P3_SALARY; p_row.is_active:= :P3_IS_ACTIVE; modify_employees_mysql(:REQUEST, p_row, :p3_checksum); END;
And now you have it – APEX running on another database 🙂