Tag: asm
- Written by: ilmarkerm
- Category: Blog entry
- Published: December 7, 2024
This is more of a story type post, motivated by encountering a Linux(?) anomaly that confused me a lot and reaching out to the community for some clarification on the matter. The story is simplified.
It all begins with the fact, that Oracle Linux 7 is at the end of its Premier Support in December 2024. We were planning to just switch out all the hardware (hardware support contracts also expire!) when OL expires and therefore avoid any unnecessary upgrade tasks, but due to the bizarre world of large enterprises the ordering of the new hardware was stalled by business and we now were faced with the fact that the hardware delivery is a year late. And we need to upgrade Oracle Linux on existing hardware – for only 1 year runtime.
This particular system is running Oracle RAC 19.24, Oracle Grid Infrastructure 19.25, Oracle Linux 7 (Oracle Linux 8 on upgraded nodes) – both on 5.4.17 UEK kernels, ASM Filter Driver (AFD) to manage the shared disks. Shared disks come from 4 enterprise storage arrays, connected using FC, all data mirrored on ASM level between different storage arrays (NB! Really important, even expensive under current support enterprise storage arrays fail and their spare part deliveries suffer as time goes on).
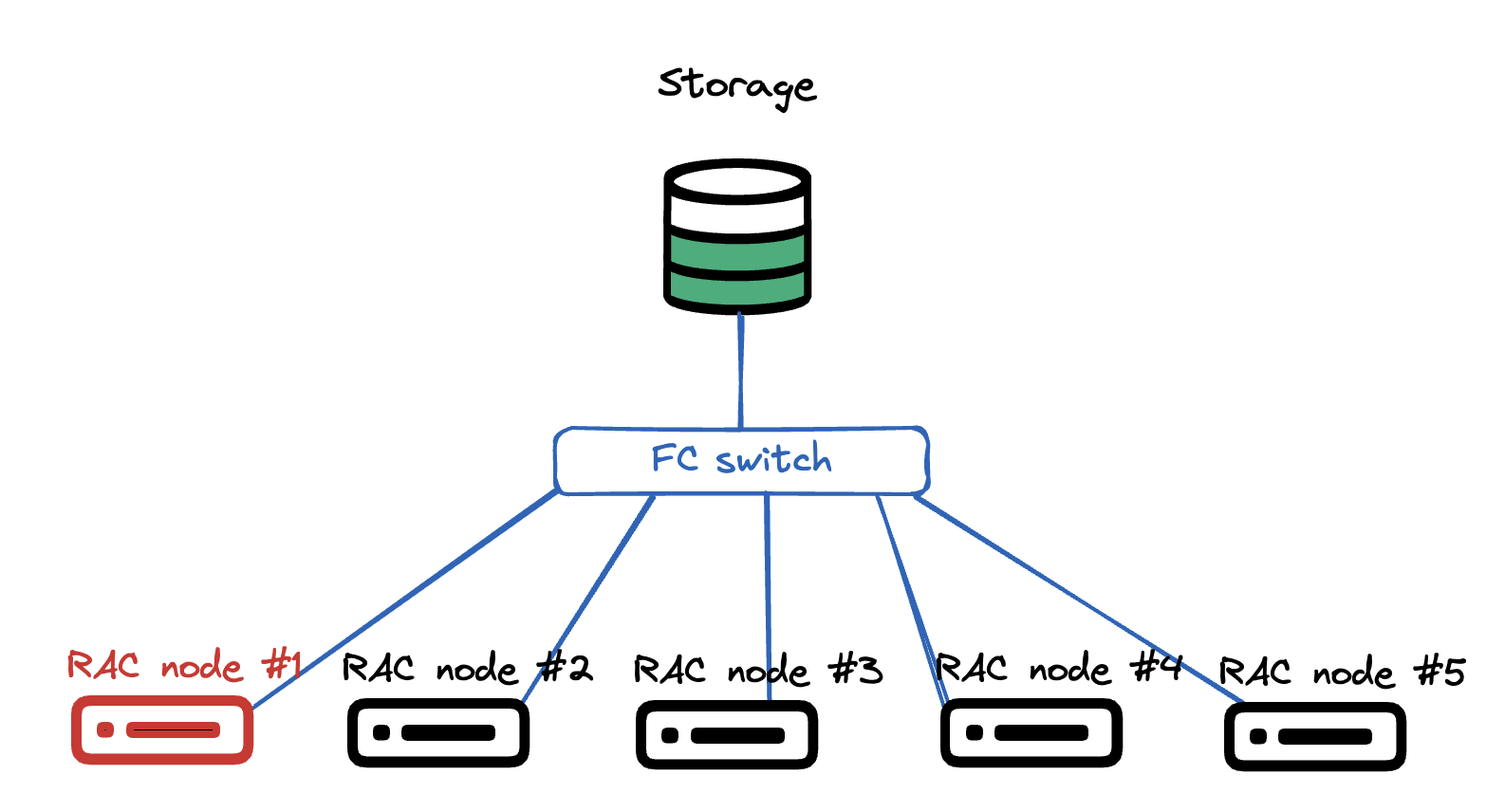
Very simplistic picture how the hardware setup looks like. Multiple compute nodes, all pure hardware, no virtualisation. All connected to the same shared LUNs via fibre channel FC. There is no storage vendor drivers, just pure Linux kernel + multipathd.
OS upgrade plan was very simple:
- Shut down one RAC instance
- Remove the node from cluster
- Disconnect all shared storage
- Install a fresh OS on the node
- Connect all shared storage
- Add the node back to cluster
- Start RAC instance
- Repeat
After I removed the first node from the cluster, handed it over to the sysadmin+storage team, they did the storage disconnect, fresh OS install, connected it back to storage and network. All seemingly well, the RAC database working without issues.
I configure OS for Oracle use, verify all networks and shared LUNs are present, then I run runcluvfy.sh stage -pre nodeadd all good, extend GI software back to new node, run root.sh… and root.sh fails (I don’t have the error message saved).
I start digging in and see that AFD can’t see any shared disks, although AFD is configured and loaded – asmcmd afd_lsdsk output is empty. AFD discovery string is correct, block devices are present in the reinstalled Linux, all looks good, but after repeated afd_scan – nothing (Lucky I didn’t use afd_scan –all).
Just to verify that I can actually read the shared block devices, I used dd to read the first 1M of some of the block devices. I prefer to use fundamental tools for a quick checkup, since they work on more low level and if they show a problem, upper layers will also have issues. Or so I thought.
[production|root@n01 tmp]# dd if=/dev/mapper/36005076810810374d80000000000000a of=/tmp/D1 bs=1M count=1
1+0 records in
1+0 records out
1048576 bytes (1.0 MB) copied, 0.00180256 s, 582 MB/sI can read the block device just fine. How about the contents? All ASM disks have a header showing the disk name, disk group name and failure groups as plain readable text.
[production|root@n01 tmp]# strings /tmp/D1
EFI PARTWhat?? That really is not correct. Were the disk headers overwritten?? Lets verify FROM A RUNNING NODE. Here it actually gets interesting.
[production|root@n03 ~]# dd if=/dev/mapper/36005076810810374d80000000000000a of=/tmp/D1 bs=1M count=1
1+0 records in
1+0 records out
1048576 bytes (1.0 MB) copied, 0.00281782 s, 372 MB/s
[production|root@n03 ~]# strings /tmp/D1
ORCLDISKDWDATA_B02IBM304_8
DWDATA_B02IBM304_8
DWDATA
R55B02READING, with dd, THE SAME DISK ON AN OLD NODE, I SEE THE CORRECT ASM DISK HEADER. This convinced me, assuming dd gives me the correct lowest level info, that the real database disks are fine, but the storage team has messed up the mappings, somehow – although the LUN UUID was the same. And the database was running fine, I didn’t really see any issues in gv$asm_disk.
Storage people started to suspect overwritten headers quite quickly, but I fought back, pointing to other nodes showing the correct headers. To make it even more confusing, also blkid tool showed different results on different nodes – confirming my (flawed) hypothesis that some mappings have been screwed up.
[production|root@n03 ~]# blkid /dev/mapper/36005076810810374d80000000000000a
/dev/mapper/36005076810810374d80000000000000a: LABEL="DWDATA_B02IBM304_8" TYPE="oracleasm"
[production|root@n02 ~]# blkid /dev/mapper/36005076810810374d80000000000000a
/dev/mapper/36005076810810374d80000000000000a: PTTYPE="PMBR"
[production|root@n01 ~]# blkid /dev/mapper/36005076810810374d80000000000000a
/dev/mapper/36005076810810374d80000000000000a: PTTYPE="gpt"Then we rebooted one instance to see what happens and when it started up – it did not find any AFD disks either and dd is showing damaged disk headers. Then I finally used Oracles own tool for debugging ASM disks – kfed read /dev/mapper/36005076810810374d80000000000000a – on an working instance where dd was still showing correct disk headers – and kfed read also confirmed that the ASM disk header was overwritten – KFBTYP_INVALID.
Time to take out: How To Restore/Repair/Fix An Overwritten (KFBTYP_INVALID) ASM Disk Header (First 4K) 10.2.0.5, 11.1.0.7, 11.2 And Onwards (Doc ID 1088867.1)
That note starts with taking a 50M backup dump, with dd, of each block device and then repairing the ASM disk header using kfed repair (all ASM disks have a backup header at a later part of the disk, which can be restored if still intact).
I quickly took a 50M dump of all block devices FROM ALL NODES – and due to the mismatched information between nodes – still hesitant of actually modifying the disks. So I made a quick and dirty python program to compare the dd dumps of the same block device between different hosts – if they differ only in the first MB or also later (in the data sections) – reporting the differences per “block”.
from pathlib import Path
basedir = Path('/nfs/shared/asmrepair')
compsource = basedir / 'n03_old_node'
compblock = 1024*1024 # 1 MiB
reportok = False
def logmsg(msg:str) -> None:
print(msg)
# find all directories that are not compsource
compdest = [ d for d in basedir.iterdir() if d.is_dir() and d != compsource ]
# Loop through all files in compsource
for sf in compsource.iterdir():
if not sf.is_file():
continue
logmsg(f"Comparing file {sf.name}")
for dd in compdest:
logmsg(f" Against {dd.name}")
tf = dd / sf.name
sfs = sf.stat()
tfs = tf.stat()
if sf.name.startswith("blkid_"):
with sf.open("r") as source, tf.open("r") as target:
if source.readline() != target.readline():
logmsg(f" LINE DOES NOT MATCH")
elif reportok:
logmsg(f" LINE ok")
else:
if sfs.st_size != tfs.st_size:
logmsg(" ERROR: Sizes do not match. Should not be here!")
continue
if sfs.st_size % compblock != 0:
logmsg(" ERROR: File size is not in full blocks")
continue
# Loop through blocks and compare
with sf.open("rb") as source, tf.open("rb") as target:
for blocknum in range(0, int(sfs.st_size/compblock)):
if source.read(compblock) != target.read(compblock):
logmsg(f" BLOCK {blocknum} DOES NOT MATCH")
elif reportok:
logmsg(f" BLOCK {blocknum} ok")This did show me that the 50M dumps only differed in the 1M area, and the rest of the contents match up. This gave enough confidence to accept the the disk headers are actually physically overwritten and dd on some nodes is just lying to me, showing some cached information.
kfed repair was able to fix almost all disk headers, and we only lost two disks that showed evidence of GRUB being installed there, so the damage was more extensive than kfed repair could handle. But, since the diskgroups were mirrored on ASM level – and, by luck, the two lost disks belonged to different diskgroups, no data was lost and downtime was very minimal (downtime happened because I tried to rescue voting file to a different shared storage, but this must have triggered afd_scan on ALL instances and cluster lost its voting disks).
It was indeed very confusing that dd lied to me, but one really good outcome from it was that I did still get the old disk headers from some nodes. And since kfed repair requires specifying ausz= parameter, when not using the old default diskgroup AU size of 1M. Since the diskgroups were already planned to be almost 1PiB in size, I ofcourse used a much larger AU size, and did not document it. But kfed read happily interpreted the 50M dd dump files as real ASM disks.
[production|root@n03 grid]# /u00/app/product/19c/bin/kfed read /nfs/shared/asmrepair/n03_old_node/DWDATA_B01IBM301_0|grep au
kfdhdb.ausize: 8388608 ; 0x0bc: 0x00800000So the final kfed repair command would be
/u00/app/product/19c/bin/kfed repair /dev/mapper/36005076810810374d80000000000000a ausz=8388608The story is a little more complex, because some not-reinstalled nodes also lost access to 1-2 disks (different disks on different nodes and one node node actually didn’t lose any).
I’m also very surprised that database just kept on working, both ASM and database alert log do report corruptions, but since all instances always had a mirror copy available, uses did not see any errors and the corruptions were repaired.
Ending part
To me the story really shows the resilience of Oracle database and ASM. Yes, the storage+sysadmin people did make a mistake of disconnecting the shared FC LUNs improperly prior OS installation. And then automated OS install wiping all connected disk headers by creating a GPT partition table there.
But in the end no data loss, no need to restore anything from backup – only minimal disruption to the database uptime (due to my attempt to rescue voting files and prevent a cluster crash). And this database is huge, creeping closer to 1PiB mark year by year and refusing to being decommissioned (or shrunk).
But… I would really like to know, why dd did lie to me, showing different disk headers on the same disk on different nodes. It properly confused me. There must be some kernel level caching ot block device headers involved?
And since “dd” and “blkid” can be subject to out-of-date cached information, the proper way do diagnose ASM disk headers is only kfed read.