Tag: data guard
Efficient test database refresh using Data Guard Snapshot Standby, Multitenant and storage snapshots
- Written by: ilmarkerm
- Category: Blog entry
- Published: March 23, 2024
There are many different ways to refresh test database with production data. Here I’m going to describe another one, that might be more on the complex side, but the basic requirements I had are:
- Data must be cleaned before opening it up for testing. Cleaning process is extensive and usually takes a few days to run.
- Switching testing from old copy to a new copy must be relatively fast. Also if problems are discovered, we should be able to switch back to the old copy relatively fast.
- Databases are large, hundreds of terabytes, so any kind of data copy over network (like PDB cloning over database link) would take unacceptable amount of time and resources.
- There is no network connection between test database network and production database network, so PDB cloning over database link is not possible anyway.
- The system should work also with databases that have a Data Guard standby with Fast-Start Failover configured.
Any kind of copying the data will not work, since the databases are really large – so some kind of storage level snapshot is needed – and we can use a modern NAS system (that databases utilise over NFS) that can do snapshots and thin clones. Although not in multiple layers.
Here is one attempt to draw out the system. With a more complicated case where the test database actually has two database instances, in Data Guard Fast-Start Failover mode.
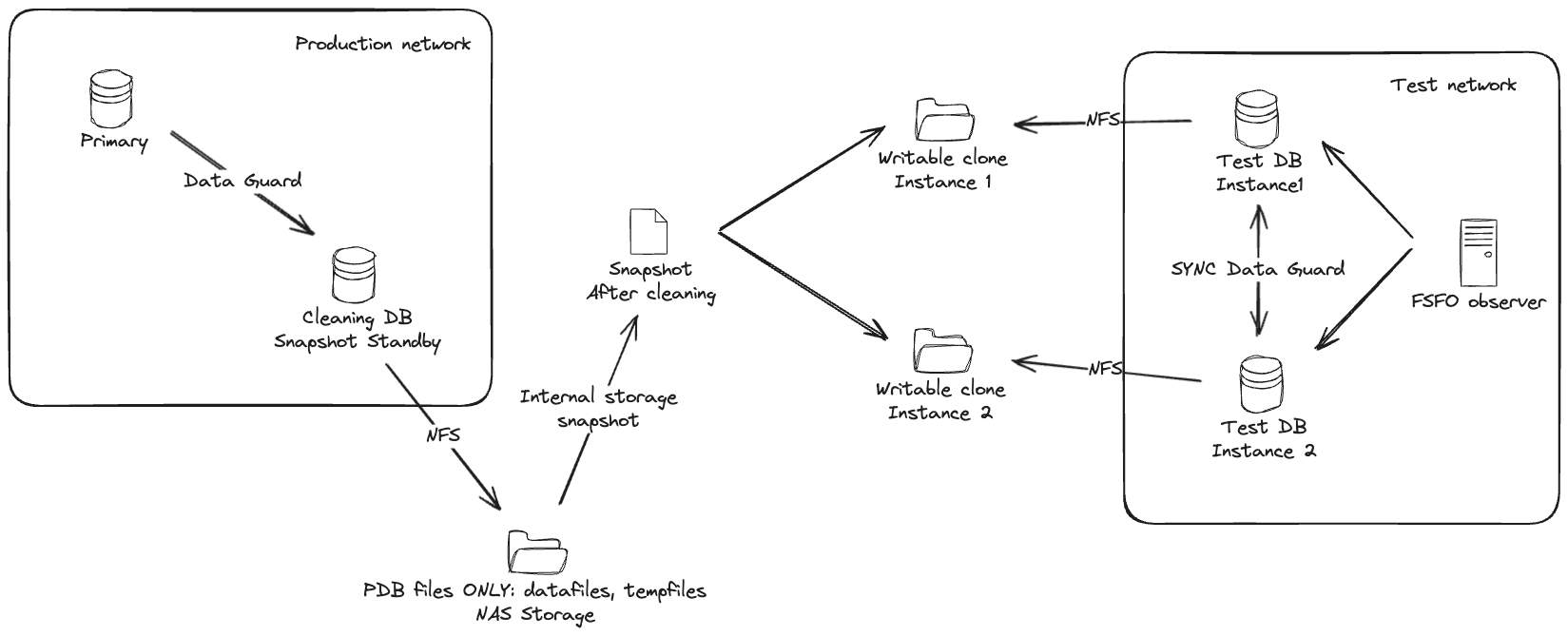
Basically:
- There is a special Data Guard standby for the cleaning process. This standby is using an external NAS storage for storing all PDB datafiles and tempfiles. No CDB files, like CDB datafiles, online logs, standby logs or recovery area should be stored in that NAS folder – keep CDB files separate.
- To start the cleaning process, put the cleaning standby in Snapshot Standby mode (instructions are here) and run all cleaning processes and scripts on the snapshot standby. After cleaning is finished successfully, create PDB metadata XML files and shut down the snapshot standby.
- Create storage level snapshot of the NAS folder storing the PDB files.
- Restore Snapshot Standby back to being a normal physical standby.
- Create writable clone from the same storage snapshot for the test database. If the test database consists of more Data Guard databases, then create a clone (from the same snapshot) for each one of them and mount them to the test database hosts.
- On the test database create a new pluggable database as clone (using NOCOPY to avoid any data movement). In case of Data Guard, do not forget to set standby_pdb_source_file_directory so the standby database would know where to find the data files of the plugged in database.
Done. Currently both old and new copy are attached to the same test CDB as independent PDBs, when you are happy with the new copy, just direct testing traffic to the new PDB. Then old one is not needed, drop it and clean up the filesystems.
Sounds maybe too complex, but the whole point is to avoid moving around large amounts of data. And key part of support rapid switching to the new copy and supporting Data Guard setups (on the test environment side) is keeping the test database CDB intact.
The steps
I have a post about using Snapshot Standby, you can read it here. All the code below is for the experts…
The preparation
Big part of the system is preparing the Cleaning DB that will be used for Snapshot Database.
Here I use the following paths:
- /oradata – Location for standby database CDB files, online logs, standby logs, recovery area
- /nfs/pdb – NFS folder from external NAS, that will ONLY store all PDB datafiles and tempfiles
# Parameters
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_create_file_dest string /nfs/pdb
db_create_online_log_dest_1 string /oradata
db_recovery_file_dest string /oradata
db_recovery_file_dest_size big integer 10T
# Datafiles
CON_ID NAME
---------- --------------------------------------------------------------------------------------------------------------------------
1 /oradata/PROD1MT101CL/datafile/o1_mf_audit_tb__0d68332o_.dbf
1 /oradata/PROD1MT101CL/datafile/o1_mf_sysaux__0d5fjj5y_.dbf
1 /oradata/PROD1MT101CL/datafile/o1_mf_system__0d4zdst4_.dbf
1 /oradata/PROD1MT101CL/datafile/o1_mf_undotbs1__0d5yw58n_.dbf
1 /oradata/PROD1MT101CL/datafile/o1_mf_users__0d65hljg_.dbf
2 /oradata/PROD1MT101CL/C24DD111D3215498E0536105500AAC63/datafile/data_D-WI93OP21_I-1717445842_TS-SYSAUX_FNO-4_q92k3val
2 /oradata/PROD1MT101CL/C24DD111D3215498E0536105500AAC63/datafile/data_D-WI93OP21_I-1717445842_TS-SYSTEM_FNO-2_p32k3v89
2 /oradata/PROD1MT101CL/C24DD111D3215498E0536105500AAC63/datafile/data_D-WI93OP21_I-1717445842_TS-UNDOTBS1_FNO-6_q22k3vag
3 /nfs/pdb/PROD1MT101CL/CC1BE00B92E672FFE053F905500A1BAE/datafile/o1_mf_audit_tb__0fbbwglb_.dbf
4 /nfs/pdb/PROD1MT101CL/C2811CAFC29D1DC9E053F905500A7EC9/datafile/o1_mf_audit_tb__0fk2wkxy_.dbf
4 /nfs/pdb/PROD1MT101CL/C2811CAFC29D1DC9E053F905500A7EC9/datafile/o1_mf_users__0fj4hm5h_.dbf
5 /nfs/pdb/PROD1MT101CL/CF6A94E61EF92940E053F905500AFB8E/datafile/o1_mf_audit_tb__0fsslsvv_.dbf
5 /nfs/pdb/PROD1MT101CL/CF6A94E61EF92940E053F905500AFB8E/datafile/o1_mf_users__0frm1yg5_.dbf
6 /nfs/pdb/PROD1MT101CL/CF6A94E61F3E2940E053F905500AFB8E/datafile/o1_mf_audit_tb__0fz8nq60_.dbf
6 /nfs/pdb/PROD1MT101CL/CF6A94E61F3E2940E053F905500AFB8E/datafile/o1_mf_users__0fy4j81x_.dbf
7 /nfs/pdb/PROD1MT101CL/CF6A94E61F832940E053F905500AFB8E/datafile/o1_mf_audit_tb__0f46dfvs_.dbf
7 /nfs/pdb/PROD1MT101CL/CF6A94E61F832940E053F905500AFB8E/datafile/o1_mf_users__0f3cn007_.dbf
8 /nfs/pdb/PROD1MT101CL/CF6A94E61FC82940E053F905500AFB8E/datafile/o1_mf_audit_tb__0g5h842b_.dbf
8 /nfs/pdb/PROD1MT101CL/CF6A94E61FC82940E053F905500AFB8E/datafile/o1_mf_users__0g2v64l9_.dbf
9 /nfs/pdb/PROD1MT101CL/05126406D61853B3E0635005500AA12B/datafile/o1_mf_audit_tb__0g9rsqpo_.dbf
9 /nfs/pdb/PROD1MT101CL/05126406D61853B3E0635005500AA12B/datafile/o1_mf_inmemory__0g8yrdvh_.dbf
# Tempfiles
CON_ID NAME
---------- -------------------------------------------------------------------------------------------------
1 /oradata/PROD1MT101CL/datafile/o1_mf_temp__0d35c01p_.tmp
2 /oradata/PROD1MT101CL/C24DD111D3215498E0536105500AAC63/datafile/o1_mf_temp__0d36q7dx_.tmp
3 /nfs/pdb/PROD1MT101CL/CC1BE00B92E672FFE053F905500A1BAE/datafile/o1_mf_temp__0gr02w4t_.tmp
3 /nfs/pdb/PROD1MT101CL/CC1BE00B92E672FFE053F905500A1BAE/datafile/o1_mf_temp__0gr0j0wr_.tmp
3 /nfs/pdb/PROD1MT101CL/CC1BE00B92E672FFE053F905500A1BAE/datafile/o1_mf_temp_dba__0gqzydts_.tmp
4 /nfs/pdb/PROD1MT101CL/C2811CAFC29D1DC9E053F905500A7EC9/datafile/o1_mf_temp__0grhwybg_.tmp
4 /nfs/pdb/PROD1MT101CL/C2811CAFC29D1DC9E053F905500A7EC9/datafile/o1_mf_temp__0grjcvk4_.tmp
4 /nfs/pdb/PROD1MT101CL/C2811CAFC29D1DC9E053F905500A7EC9/datafile/o1_mf_temp_dba__0h6slfch_.tmp
5 /nfs/pdb/PROD1MT101CL/CF6A94E61EF92940E053F905500AFB8E/datafile/o1_mf_temp__0gokwd9n_.tmp
5 /nfs/pdb/PROD1MT101CL/CF6A94E61EF92940E053F905500AFB8E/datafile/o1_mf_temp__0gol9jc6_.tmp
5 /nfs/pdb/PROD1MT101CL/CF6A94E61EF92940E053F905500AFB8E/datafile/o1_mf_temp_dba__0gokr9ng_.tmp
6 /nfs/pdb/PROD1MT101CL/CF6A94E61F3E2940E053F905500AFB8E/datafile/o1_mf_temp__0gnrh7x8_.tmp
6 /nfs/pdb/PROD1MT101CL/CF6A94E61F3E2940E053F905500AFB8E/datafile/o1_mf_temp__0gnrw0dj_.tmp
6 /nfs/pdb/PROD1MT101CL/CF6A94E61F3E2940E053F905500AFB8E/datafile/o1_mf_temp_dba__0gnrb2gg_.tmp
7 /nfs/pdb/PROD1MT101CL/CF6A94E61F832940E053F905500AFB8E/datafile/o1_mf_temp__0gmw72co_.tmp
7 /nfs/pdb/PROD1MT101CL/CF6A94E61F832940E053F905500AFB8E/datafile/o1_mf_temp__0gmwnqsp_.tmp
7 /nfs/pdb/PROD1MT101CL/CF6A94E61F832940E053F905500AFB8E/datafile/o1_mf_temp_dba__0gmw1xm3_.tmp
8 /nfs/pdb/PROD1MT101CL/CF6A94E61FC82940E053F905500AFB8E/datafile/o1_mf_temp__0gm118wt_.tmp
8 /nfs/pdb/PROD1MT101CL/CF6A94E61FC82940E053F905500AFB8E/datafile/o1_mf_temp__0gm1dv5n_.tmp
8 /nfs/pdb/PROD1MT101CL/CF6A94E61FC82940E053F905500AFB8E/datafile/o1_mf_temp_dba__0gm0wzcc_.tmp
9 /nfs/pdb/PROD1MT101CL/05126406D61853B3E0635005500AA12B/datafile/o1_mf_temp__0gj66tgb_.tmp
9 /nfs/pdb/PROD1MT101CL/05126406D61853B3E0635005500AA12B/datafile/o1_mf_temp_dba__0gh7wbpf_.tmp
# Logs
MEMBER
--------------------------------------------------------
/oradata/PROD1MT101CL/onlinelog/o1_mf_1__0b0frl6b_.log
/oradata/PROD1MT101CL/onlinelog/o1_mf_2__0b1qco5j_.log
/oradata/PROD1MT101CL/onlinelog/o1_mf_3__0b2bd0od_.log
/oradata/PROD1MT101CL/onlinelog/o1_mf_4__0b2z3qvo_.log
/oradata/PROD1MT101CL/onlinelog/o1_mf_5__0b3tkddo_.log
/oradata/PROD1MT101CL/onlinelog/o1_mf_6__0b4gvg2h_.log
/oradata/PROD1MT101CL/onlinelog/o1_mf_7__0b51zbqp_.logCleaning
# Convert the special Data Guard standby database to a snapshot standby
DGMGRL> convert database prod1mt101cl to snapshot standby;
# Now run all your cleaning scripts on this special database
SQL> @all_of_my_special_cleaning_scripts
# Cleaning is now finished successfully
# Close and reopen each PDB in READ ONLY mode
SQL> alter pluggable database all close;
SQL> alter pluggable database all open read only;
# Create XML metadata file for each PDB
SQL> exec DBMS_PDB.DESCRIBE('/nfs/pdb/apppdb1.xml','APPPDB1');
SQL> exec DBMS_PDB.DESCRIBE('/nfs/pdb/apppdb2.xml','APPPDB2');
SQL> exec DBMS_PDB.DESCRIBE('/nfs/pdb/apppdb3.xml','APPPDB3');
# Shut down the cleaning database
SQL> shutdown immediateSnapshot
Now use your NAS toolkit (REST API for example) to create a storage level snapshot from the /nfs/pdb filesystem.
Convert Snapshot Standby back to physical standby
Use the instructions in this post to restore the cleaning instance back to being a physical standby.
Attach PDBs to test database CDB
First, use your NAS toolkit to create a thin writable from from the snapshot created earlier (or multiple clones if the test setup has a Data Guard standby, a dedicated copy for each) and mount them to the test database hosts as /nfs/newclone.
# If the test setup has Data Guard, set standby_pdb_source_file_directory
alter system set standby_pdb_source_file_directory='/nfs/newclone/PROD1MT101CL/CC1BE00B92E672FFE053F905500A1BAE/datafile/' scope=memory;
# On test primary create new pluggable database as clone
create pluggable database apppdb1_newclone as clone using '/nfs/newclone/apppdb1.xml' source_file_directory='/nfs/newclone/PROD1MT101CL/CC1BE00B92E672FFE053F905500A1BAE/datafile/' nocopy tempfile reuse;
# Open it
alter pluggable database apppdb1_newclone;Done.
- Written by: ilmarkerm
- Category: Blog entry
- Published: February 28, 2024
Snapshot Standby is actually quite an old feature of Oracle Data Guard. According to note Doc ID 443720.1 it has been available since 11.2.
Snapshot Standby is a feature that allows temporarily to open existing physical standby database in READ WRITE mode – for example running some tests – and then convert it back to physical standby, discarding all the changes that were made during the testing. Another key feature is that the standby also retains some of the standby functions while it is open in READ WRITE mode, the snapshot standby keeps receiving redo from the primary database – just receiving, not applying. So even when you perform some testing on the standby, your data is still being protected by Data Guard. Although applying the shipped changes to the standby could take extended amount of time later.
Snapshot Standby relies on flashback database feature, but the process of converting back and forth is handled automatically by Data Guard Broker. But since it is creating a guaranteed restore point, then explicitly enabling flashback database is not required – although internally it is still flashback database so its restrictions apply.
My setup
DGMGRL> show configuration;
Configuration - devdbs02
Protection Mode: MaxPerformance
Members:
devdbs02i1 - Primary database
devdbs02i2 - Physical standby database
Fast-Start Failover: DisabledTwo databases in the configuration – devdbs02i1 is currently primary and devdbs02i2 is physical standby that I want to use temporarily for some testing purposes.
Converting standby to snapshot standby
Here I convert devdbs02i2 to a snapshot standby, which will open it temporarily in READ WRITE mode (independently from the primary database). All the changes made in devdbs02i2 will be flashed back (lost) when the database is converted back to physical standby later.
First make sure, that you have enough disk space for recovery area available. While the database is in snapshot standby mode, the recovery area will have to store flashback logs (for the entire duration while the standby is in snapshot standby mode!), archive logs from primary database and also archive logs from your testing activities. So quite a lot of extra pressure on the recovery area. Make it large.
$ dgmgrl /
DGMGRL for Linux: Release 19.0.0.0.0 - Production on Tue Feb 27 13:18:43 2024
Version 19.21.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
Welcome to DGMGRL, type "help" for information.
Connected to "devdbs02i2"
Connected as SYSDG.
DGMGRL> show configuration;
Configuration - devdbs02
Protection Mode: MaxPerformance
Members:
devdbs02i1 - Primary database
devdbs02i2 - Physical standby database
Fast-Start Failover: Disabled
Configuration Status:
SUCCESS (status updated 38 seconds ago)And do the conversion.
DGMGRL> convert database devdbs02i2 to snapshot standby;
Converting database "devdbs02i2" to a Snapshot Standby database, please wait...
Database "devdbs02i2" converted successfully
DGMGRL> show configuration verbose;
Configuration - devdbs02
Protection Mode: MaxPerformance
Members:
devdbs02i1 - Primary database
devdbs02i2 - Snapshot standby databaseSo, now devdbs02i2 is in snapshot standby mode, meaning it is open READ WRITE for temporary testing purposes.
SYS @ devdbs02i2:>select open_mode, database_role from v$database;
OPEN_MODE DATABASE_ROLE
-------------------- ----------------
READ WRITE SNAPSHOT STANDBYData Guard Broker has automatically created a guaranteed restore point for us. And looks like the developer who wrote this piece of code was american and used their non-standard date format 🙁 Kudos for using standard time format tho 🙂
SYS @ devdbs02i2:>select con_id, name, GUARANTEE_FLASHBACK_DATABASE from v$restore_point;
CON_ID NAME GUA
---------- ---------------------------------------------- ---
0 SNAPSHOT_STANDBY_REQUIRED_02/27/2024 13:20:13 YESAnd devdbs02i2 still keeps receiving redo from the primary database. This is one key benefit of using a snapshot standby.
SYS @ devdbs02i2:>select process,status,thread#,sequence#,block# from v$managed_standby where process='RFS';
PROCESS STATUS THREAD# SEQUENCE# BLOCK#
--------- ------------ ---------- ---------- ----------
RFS IDLE 1 0 0
RFS IDLE 1 7 4029
RFS IDLE 0 0 0And primary database still keeps sending the redo
SYS @ devdbs02i1:>select process,status,thread#,sequence#,block# from v$managed_standby where process='LGWR';
PROCESS STATUS THREAD# SEQUENCE# BLOCK#
--------- ------------ ---------- ---------- ----------
LGWR WRITING 1 7 4078What I also notice is that the snapshot standby incarnation has changed (as expected). The snapshot standby is on incarnation 31, while the primary database is still on 30.
SYS @ devdbs02i2:>select LAST_OPEN_INCARNATION# from v$database;
LAST_OPEN_INCARNATION#
----------------------
31
SYS @ devdbs02i1:>select LAST_OPEN_INCARNATION# from v$database;
LAST_OPEN_INCARNATION#
----------------------
30Using the stapshot standby in read write mode
Nothing special about it, just connect and run your statements.
SYS @ devdbs02i2:>alter session set container=lbtest1;
Session altered.
SYS @ devdbs02i2:>create table ilmker.just_some_test_data as select * from all_objects union all select * from all_objects;
Table created.Restoring the database to physical standby
After your testing is done you should return the database back to being physical standby. Before the recovery area diskspace runs out.
First mount the snapshot standby instance.
SYS @ devdbs02i2:>shu immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SYS @ devdbs02i2:>startup mountThen connect to Broker using SYSDG privileges. With password! Broker needs to connect to the primary database, so it needs the password this time.
$ dgmgrl c##dataguard@devdbs02-2.db.example.net/devdbs02i2.dev.mt1
DGMGRL for Linux: Release 19.0.0.0.0 - Production on Wed Feb 28 16:22:02 2024
Version 19.21.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
Welcome to DGMGRL, type "help" for information.
Password:
Connected to "devdbs02i2"
Connected as SYSDG.
DGMGRL> show configuration;
Configuration - devdbs02
Protection Mode: MaxPerformance
Members:
devdbs02i1 - Primary database
devdbs02i2 - Snapshot standby database
Warning: ORA-16782: instance not open for read and write access
DGMGRL> convert database devdbs02i2 to physical standby;
Converting database "devdbs02i2" to a Physical Standby database, please wait...
Operation requires a connection to database "devdbs02i1"
Connecting ...
Connected to "DEVDBS02I1"
Connected as SYSDG.
Database "devdbs02i2" converted successfully
DGMGRL> show configuration;
Configuration - devdbs02
Protection Mode: MaxPerformance
Members:
devdbs02i1 - Primary database
devdbs02i2 - Physical standby databaseAnd devdbs02i2 is back as serving as physical standby database. Really convenient feature.
Why was I writing about this quite old feature? I was exploring it for the purpose of using it to refresh our performance test databases, because they are very large, they require cleaning of PII data and we need to complete the switch to a new copy in a very short time frame. But that story is for another post.
- Written by: ilmarkerm
- Category: Blog entry
- Published: March 11, 2023
Here is a list of things that I think are important to monitor if you have Data Guard FSFO setup. All the mentioned things are intended for automated monitoring – things to raise alerts on.
My goal is to get as much information as possible from one place – the primary database. Since the primary database is alwas open and you can always connect your monitoring agent there.
This is about Oracle 19c (19.16.2 at the time of writing).
Here I’m also assuming Data Guard protection mode is set to MaxAvailability (or MaxProtection).
The overall status of Data Guard broker
I think the best way to get a quick overview of Data Guard health is to query V$DG_BROKER_CONFIG. It can be done from primary and it gives you a quick status for each destination.
SYS @ failtesti2:>SELECT database, dataguard_role, enabled, status
FROM V$DG_BROKER_CONFIG;
DATABASE DATAGUARD_ROLE ENABL STATUS
------------ ------------------ ----- ----------
failtesti1 PHYSICAL STANDBY TRUE 0
failtesti2 PRIMARY TRUE 0
failtesti3 PHYSICAL STANDBY TRUE 16809STATUS column is the most interesting. It gives you the current ORA error code for this destination. If it is 0 – ORA-0 means “normal, successful completion”.
Is FSFO target SYNCHRONIZED?
In case Fast-Start Failover is enabled – you need to be alerted if the FSFO target becomes UNSYNCHRONIZED. You can query it from V$DATABASE.
SYS @ failtesti2:>SELECT FS_FAILOVER_MODE, FS_FAILOVER_STATUS, FS_FAILOVER_CURRENT_TARGET, FS_FAILOVER_THRESHOLD
FROM V$DATABASE;
FS_FAILOVER_MODE FS_FAILOVER_STATUS FS_FAILOVER_CURRENT_TARGET FS_FAILOVER_THRESHOLD
------------------- ---------------------- ------------------------------ ---------------------
ZERO DATA LOSS SYNCHRONIZED failtesti1 25
-- After bouncing failtesti1
SYS @ failtesti2:>SELECT FS_FAILOVER_MODE, FS_FAILOVER_STATUS, FS_FAILOVER_CURRENT_TARGET, FS_FAILOVER_THRESHOLD
FROM V$DATABASE;
FS_FAILOVER_MODE FS_FAILOVER_STATUS FS_FAILOVER_CURRENT_TARGET FS_FAILOVER_THRESHOLD
------------------- ---------------------- ------------------------------ ---------------------
ZERO DATA LOSS UNSYNCHRONIZED failtesti1 25Alert if FS_FAILOVER_STATUS has been UNSYNCHRONIZED for too long.
Is Observer connected?
In FSFO you also need to alert if observer is no longer present. If there is no observer, FSFO will not happen and you also loose quorum. If both standby database and observer are down – primary databases loses quorum and also shuts down.
Again, you can query V$DATABASE from the primary database.
SYS @ failtesti2:>SELECT FS_FAILOVER_MODE, FS_FAILOVER_CURRENT_TARGET, FS_FAILOVER_OBSERVER_PRESENT, FS_FAILOVER_OBSERVER_HOST
FROM V$DATABASE;
FS_FAILOVER_MODE FS_FAILOVER_CURRENT_TARGET FS_FAIL FS_FAILOVER_OBSERVER_HOST
------------------- ------------------------------ ------- ------------------------------
ZERO DATA LOSS failtesti1 YES failtest-observer
-- After stopping the observer
SYS @ failtesti2:>SELECT FS_FAILOVER_MODE, FS_FAILOVER_CURRENT_TARGET, FS_FAILOVER_OBSERVER_PRESENT
FROM V$DATABASE;
FS_FAILOVER_MODE FS_FAILOVER_CURRENT_TARGET FS_FAIL
------------------- ------------------------------ -------
ZERO DATA LOSS failtesti1 NOAlert if FS_FAILOVER_OBSERVER_PRESENT has been NO for too long.
Is the protection mode as intended?
Good to monitor to avoid DBA human errors. Maybe a DBA lowered the protection mode and forgot to reset it back to the original value. Again this information is available on V$DATABASE. Probably not needed, but it is an easy and check check.
SYS @ failtesti2:>SELECT PROTECTION_MODE, PROTECTION_LEVEL
FROM V$DATABASE;
PROTECTION_MODE PROTECTION_LEVEL
-------------------- --------------------
MAXIMUM AVAILABILITY MAXIMUM AVAILABILITYMonitoring Apply and Transport lag
Probably this is one of the most asked about things to monitor about Data Guard. And the obvious way to do it is via Data Guard Broker.
First – you have ApplyLagThreshold and TransportLagThreshold properties for each database and if that is breached, Data Guard Broker will raise an alarm – the database status will change.
-- On my standby database I have ApplyLagThreshold and TransportLagThreshold set
DGMGRL> show database failtesti3 ApplyLagThreshold;
ApplyLagThreshold = '30'
DGMGRL> show database failtesti3 TransportLagThreshold;
TransportLagThreshold = '30'
-- I do breach both of the thresholds
DGMGRL> show database failtesti3;
Database - failtesti3
Role: PHYSICAL STANDBY
Intended State: APPLY-ON
Transport Lag: 1 minute 38 seconds (computed 49 seconds ago)
Apply Lag: 1 minute 38 seconds (computed 49 seconds ago)
Average Apply Rate: 6.00 KByte/s
Real Time Query: ON
Instance(s):
failtesti3
Database Warning(s):
ORA-16853: apply lag has exceeded specified threshold
ORA-16855: transport lag has exceeded specified threshold
ORA-16857: member disconnected from redo source for longer than specified threshold
Database Status:
WARNING
-- If I query V$DG_BROKER_CONFIG from PRIMARY the status reflects that
SYS @ failtesti2:>SELECT database, dataguard_role, status
FROM V$DG_BROKER_CONFIG;
DATABASE DATAGUARD_ROLE STATUS
--------------- ------------------ ----------
failtesti1 PHYSICAL STANDBY 0
failtesti2 PRIMARY 0
failtesti3 PHYSICAL STANDBY 16809
$ oerr ora 16809
16809, 00000, "multiple warnings detected for the member"
// *Cause: The broker detected multiple warnings for the member.
// *Action: To get a detailed status report, check the status of the member
// specified using either Enterprise Manager or the DGMGRL CLI SHOW
// command.
-- If I fix the transport lag
SYS @ failtesti2:>SELECT database, dataguard_role, status
FROM V$DG_BROKER_CONFIG;
DATABASE DATAGUARD_ROLE STATUS
--------------- ------------------ ----------
failtesti1 PHYSICAL STANDBY 0
failtesti2 PRIMARY 0
failtesti3 PHYSICAL STANDBY 16853
$ oerr ora 16853
16853,0000, "apply lag has exceeded specified threshold"
// *Cause: The current apply lag exceeded the value specified by the
// ApplyLagThreshold configurable property. It may be caused either by
// a large transport lag or poor performance of apply services on the
// standby database.
// *Action: Check for gaps on the standby database. If no gap is present, tune
// the apply services.Really good for monitoring and the monitoring agent only needs to connect to the primary database. If status != 0, we have a problem.
OK good, but that will only tell you that the threshold was breached – but how big is the lag actually? Managers like charts. If you can query from standby database, V$DATAGUARD_STATS is your friend.
-- Has to be executed from standby database
WITH
FUNCTION interval_to_seconds(p_int interval day to second) RETURN number
DETERMINISTIC
IS
BEGIN
-- Converts interval to seconds
RETURN
extract(day from p_int)*86400+
extract(hour from p_int)*3600+
extract(minute from p_int)*60+
extract(second from p_int);
END;
SELECT name, interval_to_seconds(to_dsinterval(value)) lag_s
FROM v$dataguard_stats
WHERE name IN ('transport lag','apply lag')Another view to get more details about the apply process is V$RECOVERY_PROGRESS. Again have to query it from the standby database itself. You can see apply rates for example from there.
What if you can not (do not want to) connect to (each) standby database, maybe it is in MOUNTED mode (I object to connecting remotely as SYS)? How to get standby lag querying from primary database?
Documented option is to query V$ARCHIVE_DEST, not great and does not work for cascaded destinations.
SYS @ failtesti2:>SELECT dest_id, dest_name, applied_scn, scn_to_timestamp(applied_scn)
FROM v$archive_dest
WHERE status = 'VALID' and applied_scn > 0;
DEST_ID DEST_NAME APPLIED_SCN SCN_TO_TIMESTAMP(APPLIED_SCN)
---------- -------------------- ----------- -----------------------------
2 LOG_ARCHIVE_DEST_2 409036447 2023-03-11 07:40:00
3 LOG_ARCHIVE_DEST_3 409173280 2023-03-11 07:41:27Not really great for monitoring.
Is there a possibility to query Broker data from primary database? Currently not in a documented way.
-- Query from Broker. NB! DBMS_DRS is currently undocumented.
-- X$DRC is X$, so it will never be documented, and you can only query it as SYS/SYSDG.
SYS @ failtesti2:>SELECT value database_name, dbms_drs.get_property_obj(object_id, 'ApplyLag') apply_lag
FROM x$drc
WHERE attribute='DATABASE' and value != 'failtesti2';
DATABASE_NAM APPLY_LAG
------------ ------------
failtesti1 0 0
failtesti3 1174 40
-- As a comparison
SYS @ failtesti2:>SELECT dest_id, dest_name, applied_scn, cast(systimestamp as timestamp) - scn_to_timestamp(applied_scn) lag
FROM v$archive_dest
WHERE status = 'VALID' and applied_scn > 0;
DEST_ID DEST_NAME APPLIED_SCN LAG
---------- -------------------- ----------- ------------------------------
2 LOG_ARCHIVE_DEST_2 409036447 +000000000 00:20:13.863936000
3 LOG_ARCHIVE_DEST_3 411005382 +000000000 00:00:40.863936000
-- Comparing these numbers it seems to me that "1174 40" should be interpreted as "lag_in_seconds measurement_age_in_seconds"
-- So failtesti3 had 1174 seconds of lag measured 40 seconds ago
-- The same also works for TransportLag
SYS @ failtesti2:>SELECT value database_name, dbms_drs.get_property_obj(object_id, 'TransportLag') transport_lag
FROM x$drc
WHERE attribute='DATABASE' and value != 'failtesti2';
DATABASE_NAM TRANSPORT_LAG
------------ -------------
failtesti1 0 0
failtesti3 107 56Also – my favourite actually – if you have Active Data Guard licence and the standby is open – just have a pinger job in primary database updating a row every minute (or 30s??) to the current UTC timestamp sys_extract_utc(systimestamp). And have your monitoring agent check on the standby side how old that timestamp is. It is my favourite, because it is a true end-to-end check, it does not depend on any dark unseen Data Guard inner workings and wonderings if the reported numbers by Broker are correct.
Is MRP running (the apply process)?
Monitoring lag via Broker is great, but if by DBA accident you set APPLY-OFF for a maintenance – and forget to start it again. Since administrator has told Broker that APPLY should be OFF, Broker will not raise ApplyLag warnings anymore. So if Failover happens – it will be very slow, since it also needs to apply all the missing logs.
-- To demonstrate the problem
DGMGRL> show database failtesti3 ApplyLagThreshold;
ApplyLagThreshold = '30'
-- ApplyLagThreshold is 30s and current Apply Lag is 25 min, but status is SUCCESS!
-- This is because Intended State: APPLY-OFF
DGMGRL> show database failtesti3;
Database - failtesti3
Role: PHYSICAL STANDBY
Intended State: APPLY-OFF
Transport Lag: 0 seconds (computed 1 second ago)
Apply Lag: 25 minutes 3 seconds (computed 1 second ago)
Average Apply Rate: (unknown)
Real Time Query: OFF
Instance(s):
failtesti3
Database Status:
SUCCESS
-- Same from primary, failtesti3 has status=0
SYS @ failtesti2:> SELECT database, dataguard_role, enabled, status
FROM V$DG_BROKER_CONFIG;
DATABASE DATAGUARD_ROLE ENABL STATUS
------------ ------------------ ----- ----------
failtesti1 PHYSICAL STANDBY TRUE 0
failtesti2 PRIMARY TRUE 0
failtesti3 PHYSICAL STANDBY TRUE 0
-- Sure will still show Apply Lag from Broker
SYS @ failtesti2:> SELECT value database_name, dbms_drs.get_property_obj(object_id, 'ApplyLag') apply_lag
FROM x$drc
WHERE attribute='DATABASE' and value = 'failtesti3';
DATABASE_NAM APPLY_LAG
------------ ------------
failtesti3 1792 0How to check that all targets are applying? One option is to actually check on standby side, if MRP0 process is running.
SYS @ failtesti3:>SELECT process
FROM V$MANAGED_STANDBY
WHERE process = 'MRP0';
PROCESS
---------
MRP0
-- I shut down apply
DGMGRL> edit database failtesti3 set state='apply-off';
Succeeded.
-- No MRP0 anymore
SYS @ failtesti3:>SELECT process FROM V$MANAGED_STANDBY WHERE process = 'MRP0';
no rows selectedBut for automated monitoring I don’t really like to connect to each standby, especially if no Active Data Guard is in use. How to get it from primary? It gets a little tricky.
-- To check the intended state, could also go for the unsupported route.
-- APPLY-READY means APPLY-OFF
SYS @ failtesti2:>SELECT value database_name, dbms_drs.get_property_obj(object_id, 'intended_state') intended_state
FROM x$drc
WHERE attribute='DATABASE' and value = 'failtesti3';
DATABASE_NAM INTENDED_STATE
------------ --------------------
failtesti3 PHYSICAL-APPLY-READY
-- After turning APPLY-ON
DGMGRL> edit database failtesti3 set state='apply-on';
Succeeded.
SYS @ failtesti2:>SELECT value database_name, dbms_drs.get_property_obj(object_id, 'intended_state') intended_state
FROM x$drc
WHERE attribute='DATABASE' and value = 'failtesti3';
DATABASE_NAM INTENDED_STATE
------------ --------------------
failtesti3 PHYSICAL-APPLY-ONHere could check that Broker has the intended state correct for all standby databases.
Broker also has export configuration option, that could possibly be used for some automated checks. It is a documented DGMGRL command, but the resulting XML file is placed under database trace directory and the contents of that XML file are not documented.
[oracle@failtest-2 ~]$ dgmgrl / "export configuration to auto-dg-check.xml"
DGMGRL for Linux: Release 19.0.0.0.0 - Production on Sat Mar 11 09:04:17 2023
Version 19.16.2.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
Welcome to DGMGRL, type "help" for information.
Connected to "FAILTESTI2"
Connected as SYSDG.
Succeeded.
-- The result is an XML file with all interesting Broker configurations that could be used for automated monitoring
[oracle@failtest-2 ~]$ cat /u01/app/oracle/diag/rdbms/failtesti2/failtesti2/trace/auto-dg-check.xml
...
<Member MemberID="1" CurrentPath="True" Enabled="True" MultiInstanced="True" Name="failtesti1">
<DefaultState>STANDBY</DefaultState>
<IntendedState>STANDBY</IntendedState>
<Status>
<Severity>Success</Severity>
<Error>0</Error>
<Timestamp>1678525406</Timestamp>
</Status>
<Role>
<Condition>STANDBY</Condition>
<DefaultState>PHYSICAL-APPLY-ON</DefaultState>
<IntendedState>PHYSICAL-APPLY-ON</IntendedState>
</Role>
...
</Member>
...
<Member MemberID="3" CurrentPath="True" Enabled="True" MultiInstanced="True" Name="failtesti3">
<Status>
<Severity>Success</Severity>
<Error>0</Error>
<Timestamp>1678525396</Timestamp>
</Status>
<Role>
<Condition>STANDBY</Condition>
<DefaultState>PHYSICAL-APPLY-ON</DefaultState>
<IntendedState>PHYSICAL-APPLY-READY</IntendedState>
</Role>
...
</Member>
...Recovery Area
Need to cover also the basics – like Recovery Area usage. When using Data Guard you have most likely set ArchivelogDeletionPolicy to Applied On (All) Standby… or shipped, so if any of the standby databases fall behind, the recovery are on primary (or other standby databases) will also start to grow. Keep an eye on that.
Useful views: V$RECOVERY_FILE_DEST (or V$RECOVERY_AREA_USAGE to see the breakdown into individual consumers).
SELECT sys_extract_utc(systimestamp) time
, name recovery_dest_location
, round(space_limit/1024/1024/1024) size_gb
, round((space_used-space_reclaimable)/1024/1024/1024) used_gib
, round((space_used-space_reclaimable)*100/space_limit) used_pct
FROM V$RECOVERY_FILE_DESTConnecting to the alert.log topic below… if you have been slow to react on the proactive recovery area check above, always good to keep mining alert.log for ORA-19809. If that is seen, raise the highest immediate alert – recovery area is full and archiving is stopped.
Alert.log
Always a good idea to keep an eye on important messages from alert.log even if they are not directly related to Data Guard. I’ve blogged about how I mine and monitor alert.log here.
What to alert on? Anything where level < 16 also keep an eye on if comp_id=’VOS’.
System wait events
In case of using FSFO, your standby database is most likely in SYNC or FASTSYNC mode, this is having an impact on end user commit times. So good to keep an eye on commit timings.
V$SYSTEM_EVENT is a good view for this, but you have to sample it regularly and report on the deltas.
-- Need to sample this regularly. Report on deltas.
SELECT sys_extract_utc(systimestamp) sample_time, event
, time_waited_micro_fg
, time_waited_micro
FROM v$system_event
WHERE event in ('log file sync','log file parallel write','Redo Transport MISC','SYNC Remote Write');<RANT/>
Please only use UTC times (or TIMESTAMP WITH TIME ZONE) when developing your internal monitoring (or any other software). This is the global time standard for our planet. It is always growing, no strange jumps, everyone knows what it is. Local times belong only to the user interface layer.
Did I miss anything?
Most likely – but please tell me! I’m very interested in getting Data Guard FSFO monitoring rock solid.
Oracle REST Data Services
Recently ORDS also added a REST interface to query Data Guard properties. I have not yet checked it out, but potential for monitoring is high – especially to get around using the undocumented features.
At minimum need to trace what queries it is executing in the background to replicate them for custom monitoring 🙂