Author: ilmarkerm
- Written by: ilmarkerm
- Category: Blog entry
- Published: October 11, 2023
Scheduler agent is a way to execute external programs from database DBMS_SCHEDULER on a remote host. I started using it after analytics teams started using OS scripts more and more heavily and their team grew more and more and they started making demands what OS packages to install and making restrictions on database server OS upgrades. And sometimes their OS scripts started to consume more resources or just hung. Enough was enough, no developer can log into database server, none of their scripts can execute on the database host.
Oracle created a solution for that in 11.2 – Scheduler agent – a small java application that executes programs on the DBMS_SCHEDULER behalf and communicates back the results. When creating an executable scheduler job, you can specify DESTINATION_NAME parameter and instead of database host the external script would be executed on a remote host instead, while keeping all the existing functionality – scheduler would know when script execution finished and would also get its exit code, stdout and stderr. Often these scripts were used to download a remote file that later was processed using Oracle external table – so the script execution server and database had to use the same filesystem – we used NFS share from a central NAS.
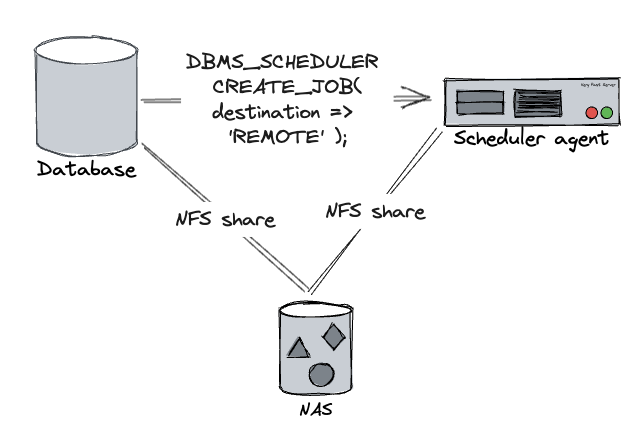
All worked perfectly, no hiccups in 11.2 and 12.1. But then came 19c and Oracle added a restriction that when registering database on the scheduler agent side, database and scheduler agent versions must match exactly – but at the same time there were multiple bugs where they never seemed to bother to update the version strings properly – so it was rather impossible to register >19.3 database without going through Oracle support for a few years. And the official scheduler agent installation documentation is still incorrect.
Here is how to set up scheduler agent in current 19c versions (tested with 19.18, 19.19, 19.20).
On the database server, on the database ORACLE_HOME generate the execution agent package. It does not have to be the same database home that will connect to the agent, just the same version is enough (same RU). This is a self-contained zip file that contains everything needed (including JRE) to run the scheduler agent on a remote host.
# Check that ORACLE_HOME and ORACLE_SID are set properly
# If ORACLE_SID is incorrect extjobo will return "ORACLE_SID not found"
# NB! For some reason I also get "ORACLE_SID not found" when running the
# command under RAC database home with correct ORACLE_SID set!
# Works fine under single instance database home (and host running only one instance)
$ echo $ORACLE_SID
qa1i1
$ echo $ORACLE_HOME
/u01/app/oracle/product/19-db-19201
# Create the scheduler agent package
$ORACLE_HOME/bin/extjobo -createagentzip /tmp/execution_agent.zip
Transport /tmp/execution_agent.zip to the scheduler agent host and unzip it.
cd /u01/app/oracle/product
unzip /tmp/execution_agent.zip
# as root
/u01/app/oracle/product/execution_agent/root.shTo configure the scheduler agent, edit file /u01/app/oracle/product/execution_agent/schagent.conf. At minimum, edit the PORT value (port where scheduler agent will listen for incoming requests – needs to be open for the database server). I would also recommend changing AGENT_NAME, by default this will be agent server hostname, but you probably want to move it around between different servers and still keep the same destination name on database side.
In order to start the scheduler agent automatically, SystemD unit file will be helpful. Create file /etc/systemd/system/scheduleragent.service
[Unit]
Description=Oracle 19c scheduler agent
After=syslog.target network.target
[Service]
User=oracle
Group=oinstall
Restart=on-failure
RestartSec=30
Type=forking
PIDFile=/u01/app/oracle/product/execution_agent/data/agent.pid
# Systemd version 231 adds support for + prefix (running with privileged user)
ExecStartPre=+/usr/bin/touch /u01/app/oracle/product/execution_agent/data/pendingjobs.dat
ExecStartPre=+/bin/chown oracle:oinstall /u01/app/oracle/product/execution_agent/data/pendingjobs.dat
ExecStart=/u01/app/oracle/product/execution_agent/bin/schagent -start
ExecStop=/u01/app/oracle/product/execution_agent/bin/schagent -stop
[Install]
WantedBy=multi-user.targetEnable and start the scheduleragent service
# as root
systemctl daemon-reload
systemctl enable scheduleragent
systemctl start scheduleragentAfter that you can register database target using the regular /u01/app/oracle/product/execution_agent/bin/schagent -registerdatabase command. Agent log is in file /u01/app/oracle/product/execution_agent/data/agent.log. To increase logging verbosity change LOGGING_LEVEL=ALL in schagent.conf and restart the agent.
- Written by: ilmarkerm
- Category: Blog entry
- Published: August 5, 2023
Tim has written an excellent blog post on how to connect your APEX application with Azure SSO. I used this article as a base with my work, with a few modifications.
You can also set Authentication provider to OpenID Connect Provider, then you only have to supply one Azure SSO configuration URL, everything else will be automatically configured. Documentation is here. You can configure like that:
- Authentication provider: OpenID Connect Provider
- Discovery URL: https://login.microsoftonline.com/your_Azure_AD_tenant_UUID_here/v2.0/.well-known/openid-configuration
For Oracle Wallet setup, you can use my solution to automatically convert Linux system trusted certificates to Oracle Wallet format.
Another requirement for me was to make some Azure user group membership available for the APEX application. One option to query this from APEX is to make a post authentication call to Azure GraphQL endpoint /me/memberOf. For this to work, Azure administrator needs to grant your application User.Read privilege at minimum. Then /me/memberOf will list you only the group object ID-s that the logged in user is a member, but no group names nor other information (if you require to see group names, then your application also needs Group.Read.All permission, but for my case it required approvals and more red tape that I really did not want to go through).
The solution below is to create APEX post authentication procedure that will store the Azure enabled roles in APEX user session collection APP_USER_ENABLED_ROLES. Afterwards you can use the collection in APEX application as you see fit, also use it in APEX authorization schemes.
- Written by: ilmarkerm
- Category: Blog entry
- Published: August 2, 2023
If you need to make HTTPS requests (or other TLS secured network requests) from Oracle database, you also need a wallet containing the certification authority (CA) certificates you trust. In todays distributed web world it is quite painful to keep updated. But operating systems and popular web browsers already come with bundled trust lists – the certificate authorities the OS vendor has considered trustworthy according to their policies. Wouldn’t it be nice to make it usable for Oracle Database?
Enterprise linuxes have package ca-certificates that contain the CA-s Mozilla has deemed trustworthy, this is available in file /etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem
Oracle Wallet is basically PKCS#12 container, so we can just use standard openssl command to generate it.
I tested it with Oracle Database 19.18 and it accepted the generated file without any problems.
- Written by: ilmarkerm
- Category: Blog entry
- Published: July 20, 2023
In order to prepare for APEX 23.1 upgrade in production, I upgraded several test environments from existing 21.1.5 to 23.1.3. Nothing special about the upgrade, no errors. But then developers requested I downgrade one of the environments back to 21.1, since they needed to make some changes to existing apps.
APEX downgrade should be easy, since APEX always installs new version into a new schema (23.1 goes to APEX_230100, 21.1 is installed in APEX_210100) and then it just copies over the application metadata. Downgrade then it should be easy, just point APEX back to the old schema. Downgrade is documented and Oracle does provide apxdwngrd.sql script for it.
After running apxdwngrd.sql and dropping APEX_230100 schema – the users started receiving a page from ORDS that “Application Express is currently unavailable”.
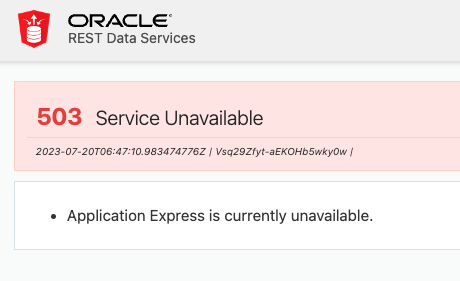

No other information, no other error message in ORDS logs, no errors in alert.log. How does it determine that APEX is unavailable? No idea.
I did the usual checks, I saw ORDS sessions connected to the database, so there were no connection issues.
SQL> select * from dba_registry where comp_id='APEX';
version = 21.1.5
status = VALID
procedure = VALIDATE_APEX
SQL> exec sys.validate_apex;
PL/SQL procedure successfully completed.
SQL> select * from dba_registry where comp_id='APEX';
version = 21.1.5
status = VALID
APEX component in the database is valid, with correct version and after validation it is still VALID.
SQL> select count(*) from dba_objects where owner='APEX_210100' and status != 'VALID';
0There are no invalid objects in the APEX schema, but I did see some public synonyms still left over from APEX 23.1. And then recreated all APEX 21.1 public synonyms.
SQL> select 'drop public synonym '||synonym_name||';' from dba_synonyms where owner='PUBLIC' and table_owner like 'APEX_230100';
... cleaned them up
SQL> alter session set current_schema = APEX_210100;
SQL> exec wwv_flow_upgrade.recreate_public_synonyms('APEX_210100');No help… Still the same “Application Express is currently unavailable” to the users.
After that I got a useful tip in twitter to check view APEX_RELEASE.

Version is correct, but PATCH_APPLIED=APPLYING? That cannot be right and checking the not yet upgraded source production database it said PATCH_APPLIED=APPLIED.
First I tried to reapply 21.1.5 patch, and then 21.1.7 patch, but none of them reset this PATCH_APPLIED field.
Time to dig into APEX internals. I see that PATCH_APPLIED field is populated using function call wwv_flow_platform.get_patch_status_and_init_cgi but the code for it is wrapped. We also have the good old SQL trace that showed me that this fuction is calling
SELECT VALUE FROM APEX_210100.WWV_FLOW_PLATFORM_PREFS WHERE NAME = 'APEX_PATCH_STATUS';And there is see value APPLYING as a plain string. What if I just update it?
update APEX_210100.WWV_FLOW_PLATFORM_PREFS set value='APPLIED' WHERE NAME = 'APEX_PATCH_STATUS';And the “Application Express is currently unavailable” message is gone and APEX works again! My guess is that something in the 23.1 upgrade process sets the old schema to APPLYING mode and then downgrade does not reset it. Sounds like a bug.
NB! Don’t do it in production – talk to Oracle Support first. I only did it because it was development environment and developers wanted to get their environment back fast.
- Written by: ilmarkerm
- Category: Blog entry
- Published: May 15, 2023
I’ve been using the old good Radius authentication protocol to authenticate database accounts (created for humans) with Active Directory credentials. It may sound strange use case, specially since Oracle also advertises its own Active Directory integration (Centrally Managed Users) and also there is Kerberos. I’ve had the following problems with them:
- CMU – in order to use Active Directory passwords, AD schema needs to be modified and AD filter installed on AD side. I think the latter removes this feature from consideration.
- Kerberos – passwordless login is very tempting and if you get it running on Oracle side – definetly a feature to consider. But deploying at scale and maintaining it is a nightmare, almost impossible to automate.
Radius on the other hand – Windows domain controllers have Radius server built in and it is also very easy to deploy at large scale and maintain on Oracle database side.
Configure database server
First add the following to database sqlnet.ora. File /u01/app/oracle/radius.key is a simple text file containing just the Radius secret. 10.0.0.1 and 10.0.0.2 are my Radius servers running on Windows, both using port 1812.
# Radius authentication settings
SQLNET.RADIUS_AUTHENTICATION_PORT = 1812
SQLNET.RADIUS_SECRET=/u01/app/oracle/radius.key
SQLNET.RADIUS_AUTHENTICATION = 10.0.0.1
SQLNET.RADIUS_ALTERNATE = 10.0.0.2In the database itself set parameter os_authent_prefix to empty string:
alter system set os_authent_prefix='' scope=spfile;And create the database users IDENTIFIED EXTERNALLY, and database username must match WInodws AD username.
CREATE USER ilmker IDENTIFIED EXTERNALLY;Configure the client
The bad thing with Radius authenticated users is that the database client must also support Radius. Oracle thick driver supports it just fine, also JDBC thin driver.
When using Oracle thick client (Instatnt client), turn on Radius authentication by adding it to sqlnet.ora:
$ cat ORACLE_CLIENT_HOME/network/admin/sqlnet.ora
SQLNET.AUTHENTICATION_SERVICES=(RADIUS)After that you can use this client to log into the database using both database authenticated users and Radius authenticated users.
JDBC thin driver is a little bit trickier (tested using 21c JDBC driver)
To use Radius add the following Java VM option – but the problem with that is that you cannot use database authenticated users after turning on this option.
-Doracle.net.authentication_services='(RADIUS)'If you want to use it with SQL Developer, add the following to product.conf file
AddVMOption -Doracle.net.authentication_services='(RADIUS)'As mentioned earlier this would disable database authenticated accounts, so in case of SQL Developer changing product.conf is not desirable.
Since 19c JDBC thin driver, it is also possible to change Java properties within the connection string using EasyConnect syntax:
tcp://oracle.db.example.com:1521/application_service.domain?oracle.net.authentication_services='(RADIUS)'One bug that I discovered in JDBC thin driver support for Radius (and Oracle is still working on it) – if you use Radius together with TCPS and database server has also enabled Oracle Native Encryption – you will get the following error from JDBC driver IO Error: Checksum fail
This is rather strange error, since when using TCPS – Oracle Native Encryption should be turned off automatically, but this error comes from Native encryption checksumming. To get around it, have to disable Native Encryption checksumming from the client side – which can also be done from inside the connection string.
tcps://oracle.db.example.com:1523/application_service.domain?oracle.net.authentication_services='(RADIUS)'&oracle.net.crypto_checksum_client=REJECTED